Ian Milligan
Wgetは、コンピューターのコマンドラインで実行される、オンライン資料を取得するための便利なプログラムです。
目次
編集者の注記
本レッスンではコマンドラインを使う必要があります。コマンドラインを使用したことがなければ、the Programming HistorianのIntroduction to the Bash Programming Languageをおさらいしておくことをお勧めします。
レッスンの目標
本レッスンは中級者向けですが、初心者もついて行けるように設計されています。
Wgetは便利なプログラムで、コンピュータのコマンドラインで動かし、オンライン資料を取得することができます。
Wgetは以下の場合に使うと便利です:
- ウェブサイト全体の取得やミラーリング(全く同じコピーの作成)。このサイトには歴史的な文書が含まれているかもしれませんし、単にバックアップしたい個人のサイトかもしれません。コマンドひとつでサイト全体をコンピュータにダウンロードすることができます。
- ウェブサイトの階層における特定のファイルのダウンロード(ウェブサイトの
/papers/ディレクトリに含まれている全てのページなど、ウェブサイトの特定の部分内のすべてのウェブサイト)。
本レッスンでは、あなた自身の仕事におけるwgetの利用方法について、3つの簡単な事例を見ていきます。本レッスンの終わりには、インターネットから大量の情報を自動で素早くダウンロードできるようになっているでしょう。オンラインで歴史的な情報のリポジトリを見つけたら、すべてのファイルを1つ1つ右クリックして保存してデータセットを構築するのではなく、そのために必要な1つのコマンドを作成するスキルを身に着けることになります。
まず、注意点があります。wgetの使い方については気を付ける必要があります。疑問があればマニュアルを参照し、ここで学んだことを実践すれば大丈夫です。サーバに負荷をかけないように、コマンドには常に遅延時間を設けるべきですし、ダウンロードする速度には常に制限を設けるべきです。これらのことはどれも善良なインターネット市民の一員であるためには必要なことであり、消火栓を一度に全部開栓するのでなく、ちょろちょろと水を出すことに似ています(一度に全部開栓するのは、あなたにとっても水道会社にとっても良くないことなのです)。
ダウンロードのコマンドを書くときはできるだけ具体的に書きましょう。wgetでインターネットを丸ごとダウンロードできてしまうというジョークもあるくらいです。さすがにそれは少し大げさですが、かといって現実とそう離れていないでしょう!
では始めましょう。
ステップ1: インストール
Linuxの場合
Linuxシステムを使っているのであればwgetは既にインストールされているはずです。wgetがあるかどうか確認するためには、コマンドラインを開いてください。 'wget' と入力しEnterキーを押してください。wgetがインストールされていれば、システムは次のように返してくるはずです:
-> Missing URL.
wgetがインストールされていなければ、次のように返してきます
-> command not found.
OS XまたはWindowsを使っているのであれば、プログラムをダウンロードする必要があります。Linuxを使っているもののwgetがインストールされていないというエラーメッセージが表示された場合は、下記のOS X用の手順に従ってください。
OS Xの場合
OS Xオプション1: 望ましい方法
OS Xではwgetを取得しインストールする方法が2通りあります。最も簡単な方法はパッケージマネージャーをインストールし、それを使って自動的にwgetをインストールする方法です。後述する2つ目の方法ではコンパイルを行います。しかし、両方のケースで正しく使うためには、Appleの”Command Line Tools”をインストールしておく必要があります。これにはXCodeをダウンロードしておく必要があります。「App Store」があれば、このリンクからXCodeを簡単にダウンロード できるはずです。App Storeがなくても以下の流れに従えば問題ありません。
ダウンロードするために、Appleデベロッパー用ウェブサイトに行き、デベロッパーとして登録し、Appleデベロッパー用ダウンロード の節で正しいバージョンを見つける必要があります。2012年7月の時点で最新バージョンであるLionを使っているのであれば、メインのリンクを使えます。OSがLionでない場合は、「Looking for additional developer tools? View Downloads」(訳注:ベータ版Xcode(英語))リンクをクリックする必要があります。
無償のデベロッパの資格情報でログインすると、長いリストが表示されます。検索バーにxcodeと入力し、あなたのOSのバージョンと互換性のあるバージョンを見つけてください。正しいバージョンを見つけるためには少し時間がかかるかもしれません。例えば、Xcode 3.2はOS X 10.6 Snow Leopard用のバージョンで、3.0はOS X 10.5 Leopard用といった具合です。
データ容量の大きいダウンロードなので、少し時間がかかります。ファイルのダウンロードが完了したらインストールします。
XCodeには、”Command Line Tools”キットをインストールする必要があります。「Preferences」(環境設定)タブを開き「Downloads」(ダウンロード)をクリックし、Command Line Toolsの隣にある「Install」(インストール)をクリックします。これでパッケージマネージャーをインストールする準備ができました。
Tインストールが最も簡単なパッケージマネージャーはHomebrewでしょう。https://brew.shにアクセスして、手順を確認してください。wgetのように、OS Xには、デフォルトでは含まれていない重要なコマンドが数多く存在します。このプログラムで、必要な全ファイルのダウンロードとインストールが簡単に行えます。
Homebrewをインストールするには、ターミナルウィンドウを開いて次の通り入力してください:
/usr/bin/ruby -e “$(curl –fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)”
OS Xに搭載されているプログラミング言語Rubyを使って、Homebrewをインストールします。インストールが成功したかどうかを確認するには、次のコマンドをターミナルウィンドウに入力してください。
brew
インストールされていれば、ドキュメントオプションの一覧が表示されるはずです。全て正しく作動していることを確かめるために、もう1つコマンドを動かします。
brew doctor
Homebrewをインストールしたので、今度はwgetをインストールしなくてはいけません。これは簡単なステップです。
brew install wget
これでwgetの最新バージョンであるwget 1.14[訳注:2020年3月30日現在のwgetの最新バージョンは1.20]のダウンロードへと続きます。スクリプトが終わり、メインのウィンドウに戻ったら、ターミナルに次のコマンドを入力してください。
wget
wgetインストールされたら、次の通り表示されるでしょう。
-> Missing URL.
インストールされていなければ、次の表示が現れるでしょう。
-> command not found.
この時点で、wgetのインストールに成功しているはずです。これで次へ進む準備ができました!
OS Xオプション2
何らかの理由でパッケージマネージャーをインストールしたくない場合は、wgetのみをダウンロードすることもできます。これは、違うパッケージマネージャー(Mac Portsなど)を使っている場合や、インフラを最小限に抑えたいという場合に使える方法です。もう一度上述の手順に従ってXcodeとCommand Line Toolsセットをインストールしてください。
その後、GNUウェブサイトから未コンパイルバージョンのwgetをダウンロードし(ここでは”wget-1.13.tar.gz”をダウンロードすることにしていますが、HTTPまたはFTPダウンロードページへのリンクをたどって見つけることができます)、zipファイルを解凍し(ダブルクリックしてください)ホームディレクトリにファイルを置き(Mac上では /user/ ディレクトリになります – 例えば、筆者のユーザー名はianmilliganであり、Finderの隣の家型アイコンの隣に現れます)、ターミナルを開いてください。このチュートリアルでは、wget-1.13をダウンロードしました。
まずはwgetファイルがあるディレクトリへ移動する必要があります。ターミナルで次のように入力してください:
cd wget-1.13
ここから先のステップは、違うバージョンのwgetをダウンロードした場合でも正しく機能しますが、上述のバージョン番号 (1.13) をあなたがダウンロードしたバージョンに変える必要があることに留意してください。
次に、ファイル用の指示を作成する、つまりmakefileの必要があります。これは最終的なファイルがどのようなものになるかを示す青写真のようなものです。次のコマンドを入力してください:
./configure –with-ssl=openssl
青写真を作成したので、コンピューターにそれに従ってもらうように指示しましょう。次の通り入力してください。
make
make次に、最終的なファイルを作成する必要があります。コマンドsudoを頭に付けることで、最高レベルのセキュリティ権限でコマンドを実行できます。これにより、実際にファイルをシステムにインストールできるようになります。
sudo make install
この時点で、コンピューターのパスワードを求められるでしょう。入力してください。
これでwgetがインストールされているはずです。
Windowsの場合
最も簡単な方法は、現在動作している最新バージョンをダウンロードすることです。そのためにはこのウェブサイトにアクセスし、 wget.exe をダウンロードしてください(本レッスンの執筆時ではバージョン1.17.1であり、32-bitバイナリーをダウンロードすべきです[訳注:2020年3月30日現在ではバージョン1.20.3が最新で、32, 64ビットの両方がダウンロード可能])。当該ファイルは32-bitバイナリーカラムの2つ目のリンク、 wget.exeです。
wget.exe を C:\Windows ディレクトリに置くと、コンピューターのどこからでもwgetを利用できるようになります。これで毎回システム上1箇所のみからwgetを作動しなくて済むようになり、楽になります。このディレクトリに置いておけば、ターミナルウィンドウのどこでもコマンドを使えることをWindowsが認識してくれます。
ステップ2: Wgetの構造を学ぶ – 特定のファイルセットをダウンロード
この時点で、どのプラットフォームを使っていても同じスタート地点に立っているはずです。wgetは、OSのコマンドラインインターフェイス(MacとLinuxユーザーの場合は、これまでもPythonコマンドを使ってきた「ターミナル」)で使います。他のレッスンで使ったと思われるKomodo Editクライアントではなくコマンドラインを使う必要があります。
wgetの網羅的な文書は GNU wgetマニュアルページで確認できます。
データセットの例を見てみましょう。ActiveHistory.caのウェブサイトがホストしている全ての論文をダウンロードしたいとしましょう。これらは全てhttp://activehistory.ca/papers/に置いてありますが、/papers/ディレクトリ内に含まれているもようなものです。例えば、ウェブサイト上で公開されている9本目の論文はhttp://activehistory.ca/papers/historypaper-9/です。この構造について、あなたのコンピューター上のディレクトリとおなじようなものとして考えてください。/History/という名前のフォルダがあれば、その中には複数のファイルがある可能性が高いでしょう。同じ構造はウェブサイトについても言えるのであって、この理屈から、どのファイルをダウンロードしたいかコンピューターに伝えるのです。
全て手動でダウンロードしたい場合は、カスタムのプログラムを書くか、論文1本1本を右クリックしなくてはいけません。あなたの研究のニーズに合致する形でファイルが整理されているのであれば、wgetが最も手っ取り早いアプローチでしょう。
wgetが正しく作動していることを確認するために、次の手順を試してみてください。
作業ディレクトリ内で新しいディレクトリを作成してください。 wget-activehistory と名付けましょう。「ファインダ」または「ウィンドウ」を使うか、ターミナルウィンドウにいるなら、次の通り入力して作成できます。
mkdir wget-activehistory
どちらにせよ、これで本チュートリアルで使うディレクトリができました。ここでコマンドラインのインターフェイスを開き、wget-activehistoryディレクトリへ遷移してください。繰り返しになりますが、ディレクトリへ移動するには、次の通り入力します。
cd [directory]
ホームディレクトリ内にこのディレクトリを作成したのであれば、cd wget-activehistoryと入力すると、新しく作成したディレクトリへ移動できるはずです。
そして、次のコマンドを入力してください。
wget http://activehistory.ca/papers/
最初にメッセージが表示された後、次のような表示が現れるはずです(ただし図表や日付など、一部詳細は異なるでしょう)。
Saving to: `index.html.1′
[] 37,668 –.-K/s in 0.1s
2012-05-15 15:50:26 (374 KB/s) – `index.html.1′ saved [37668]
ここでは、論文のインデックスページであるhttp://activehistory.ca/papers/の最初のページを、新設したディレクトリにダウンロードしたのです。それを開くと、ActiveHistory.caのホームページの本文が見えるでしょう。一見すると、すでに何かをすばやくダウンロードしたことになるのです。
しかし、今ここでは全ての論文をダウンロードしたいのです。そこで、wgetにいくつかコマンドを追加する必要があります。
Wgetは以下のような一般的な構文で作動します。
wget [options] [URL]
先ほどの例で、プログラムにどこへ行くべきか示す[URL] コンポーネントについて学びました。しかし、オプションで、私たちが具体的に何をしたいのかというもう少し詳しい情報を、プログラムに与えることができます。プログラムは、変数の前にダッシュがあることで、オプションがオプションであるということを識別します。このダッシュによって、URLとオプションの違いを知らせているのです。では、コマンドをいくつか覚えましょう。
-r
再帰的な検索はwgetにとって最も重要な部分です。これは、プログラムがウェブサイトからリンクをたどって、リンク先のウェブサイトもダウンロードすることを意味しています。例えば、http://activehistory.ca/papers/にはhttp://activehistory.ca/papers/historypaper-9/へのリンクがあるので、再帰的な検索を使えばそれもダウンロードします。しかし、他の全てのリンクもたどります。ページ上のどこかにhttp://uwo.caへのリンクがあれば、それもたどってダウンロードします。デフォルトでは、-rはwgetを最初のウェブページから5ページ先までwgetを送ります。これは、最初のウェブサイトから最大5クリック分までのリンクをたどっているのです。この時点でこれはいささか見境のないものだということになるでしょう。そのため、さらにコマンドが必要になります。
–no-parent
(ダブルダッシュはコマンドのフルテキストを意味しています。全てのコマンドにはショートバージョンも用意されており、この場合は-npで動かすことができます)。
これも重要なコマンドです。これは、wgetがリンクをたどりつつ、最後の親ディレクトリを超えないように指示しています。今回のケースでは、http://activehistory.ca/papers/ の階層の一部ではないウェブサイトにはいかないことを意味しています。もし、http://niche-canada.org/projects/events/new-events/not-yet-happened-events/ といったような長いパスであれば、 /not-yet-happened-events/フォルダ内のファイルのみを見つけます。これはあなたの検索範囲を区切るために欠かせないコマンドです。
以下に図示します。
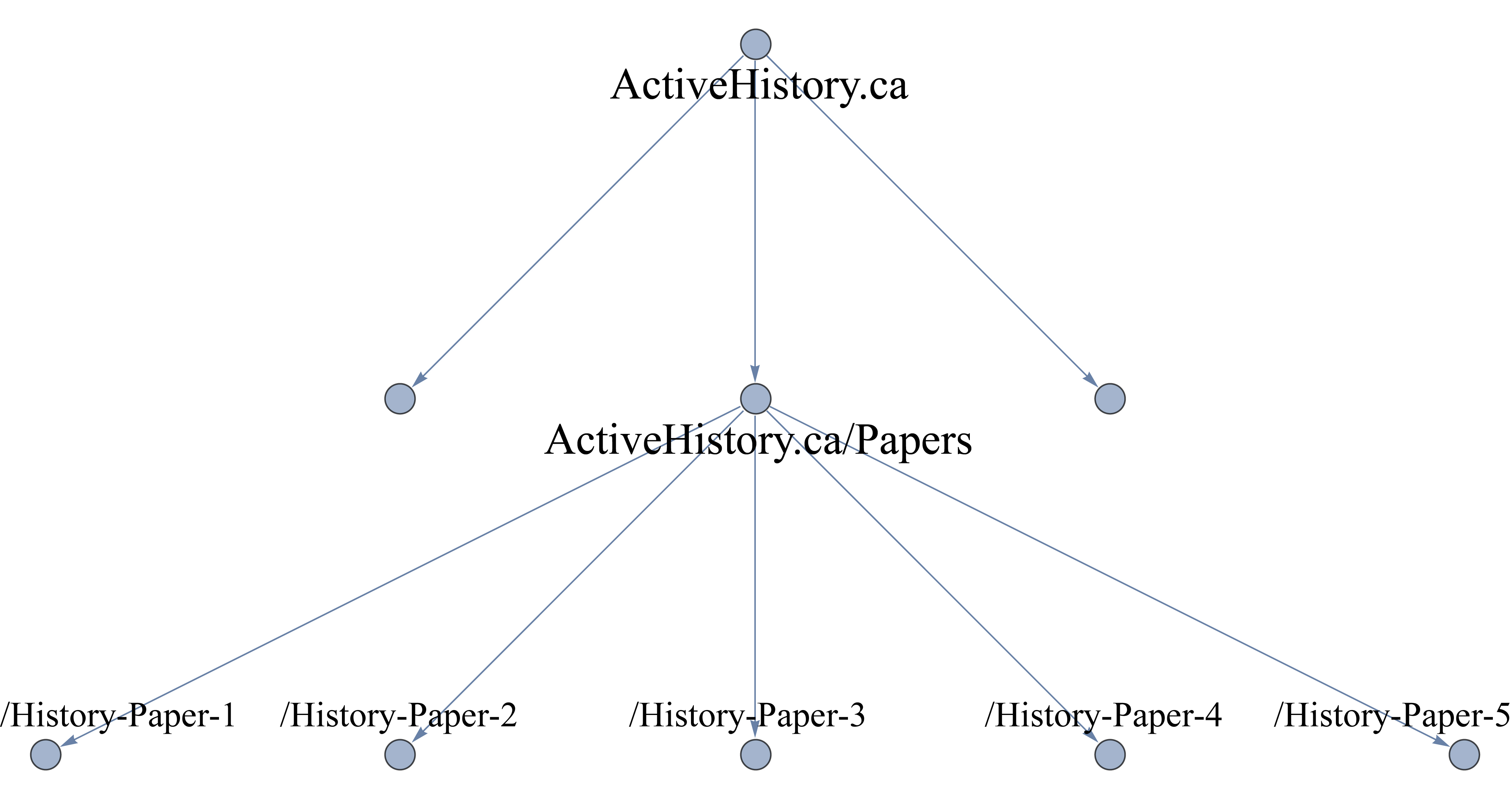
最後に、階層の外へ出たければ、どこまで行きたいか具体的にしておくのかがベストです。デフォルトでは、各リンクをたどって、あなたが提供した最初のページから最大5ページまで進むことになっています。しかし、リンクを1つだけたどってそこで止めたいとしたらどうすればよいでしょうか?その場合は -l 2, と入力すれば、ウェブページ2つ分の深さまでで止まります。これは小文字の「L」であって数字の1ではない点に注意してください。
-l 2
これらのコマンドがwgetを直接操作するのに役に立つのであれば、サーバーに優しくしてあげて、誤解から生じるサーバー攻撃への自動対応を回避するためにも、もう少しコマンドを追加する必要があります。その意味では、必須コマンドを2つ追加します。
-w 10
ウェブサーバーに一度に多くの情報を求めるの失礼です。情報を求めて待っている人たちは他にもいるので、負荷を分散させることは重要です。そのため、 -w 10 コマンドを追加することで、サーバーリクエストごとに10秒間の待ち時間を追加することができます。10秒は長すぎるので、もっと短くすることもできます。筆者の検索では、待ち時間を通常2秒に設定しています。まれに、自動ダウンロードを丸ごとブロックしているサイトに遭遇することもあるかもしれません。ウェブサイトの利用規約(本来確認すべきもの)は自動ダウンロードに関するポリシーについて触れていないかもしれませんが、それでもウェブサイトのアーキテクチャにそれを禁止するためのステップが組み込まれているかもしれません。そのようなまれなケースでは、入力した値を元に待ち時間を指定した値の0.5倍から1.5倍に変化させるコマンド ––random-wait を使えばよいでしょう。
もう一つの重要なコメントは、ダウンロードで使用する帯域幅を制限することです。
–limit-rate=20k
これも重要で丁寧なコマンドです。サーバーの帯域幅をあまり使いすぎるのはよくありません。そのため、このコマンドによって最大ダウンロード速度を20kb/sに抑えることができます。何がよい制限速度なのかは意見が分かれるところですが、容量の小さいファイルについては最大200kb/sくらいまでは大丈夫でしょう。しかし、サーバーに負担をかけないためにも、ここでは20kb/sのままにしておきましょう。これで私たち ActiveHistory.ca 側も助かります!
ステップ3: ウェブサイト全体をミラーリング
OK、ここまで来ましたので、いよいよActiveHistory.caの論文全てをダウンロードしてみましょう。URLの最後のスラッシュは重要なので注意してください – もし省いてしまうと、wgetはpapersをディレクトリではなくファイルとして認識してしまいます。ディレクトリはスラッシュで終わります。ファイルは末尾にスラッシュがありません。これでコマンドはActiveHistory.caのページ全体をダウンロードしてくれます。オプションの順番は関係ありません。
wget -r –no-parent -w 2 –limit-rate=20k http://activehistory.ca/papers/
前よりも遅くなりますが、端末はActiveHistory.caの論文を全てダウンロードし始めるでしょう。ダウンロードが終わると、 ActiveHistory.ca という名前のディレクトリの中に /papers/ というサブディレクトリが含まれているでしょう。あなたのシステムで完全にミラーリングしたのです。このディレクトリは、コマンドラインでコマンドを実行した場所に表示されるので、おそらくあなたの USERディレクトリにあるでしょう。リンクはダウンロードした他のページへの内部リンクに置き換えられているので、あなたのコンピューター上で完全に動作するActiveHistory.caウェブサイトができたことになります。これによりインターネットの速度を気にせずサイトを好きなようにいじることができるようになったのです。
ダウンロードがうまく行ったかどうか確認するためには、コマンド画面にログが表示されます。全てのファイルが正常にダウンロードされているか、確認してみてください。ダウンロードされていなければ、失敗したことを知らせてくれているはずです。
ウェブサイト全体をミラーリングしたければ、wgetに専用のコマンドが用意されています。
-m
このコマンドは「mirror」の意味であり、特にウェブサイト全体のバックアップを取るときに便利なコマンドです。このコマンドは次のようなコマンドを導入しています。タイムスタンプは、サイトの日付を見て同じバージョンが既にシステム上にあるのであれば置き換えません。(ですので、繰り返しダウンロードする時に便利です)。そして無限反復(必要な数だけサイト内のレイヤーを移動します)といったコマンドが用意されています。ActiveHistory.caのミラーリングを行うコマンドは次の通りとなります。
wget -m -w 2 –limit-rate=20k http://activehistory.ca
インターネット上のソースをダウンロードするための柔軟なツール
コマンドラインを使いこなせるようになってくると、wgetがデジタルツールキットの便利な一員だと気づくでしょう。テキストマイニングを行うために丸ごとダウンロードしたいアーカイブ文書のセットがあり、それが一つのディレクトリに全てまとめっている(思っているほど一般的ではないことです)のであれば、Pythonでリンク先のスクレイピングを行うよりも簡単なwgetのコマンドの方が早いでしょう。同様に、プログラムやファイル、バックアップなど、様々なものをコマンドラインから直接ダウンロードすることができるでしょう。
参考文献
wgetの機能についてはごく一部のスナップショットを紹介したにすぎません。詳しくは、wgetマニュアルを参照してください。
すばらしい!これで次のレッスンに進めるようになりました。
著者について
Ian Milligan氏はウォータールー大学の歴史学の准教授です。
引用の際はこちらをご利用ください
<原著>
Ian Milligan, “Automated Downloading with Wget,” The Programming Historian 1 (2012), https://programminghistorian.org/en/lessons/automated-downloading-with-wget.
<翻訳記事>
Ian Milligan著. 菊池信彦訳. Wgetを使った自動ダウンロード法. 東アジアDHポータル. 2020. https://dhportal.ac.jp/?p=502.

この 作品 は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。