Matthew Lincoln
このレッスンは廃止されました
どういう意味ですか?
the Programming Historianの編集者は、レッスン内容を維持するために最善を尽くしています。しかし、公開以来、このレッスンで使用されてきた基礎技術または原則のいずれかに大幅な変更があったことから、編集者はレッスン内容のアップデートをしないことを決定しました。このレッスンは、依然として有用な学習ツールであり、公開時においてはデジタルヒストリーの技術のスナップショットであったといえますが、今後、すべての要素が意図したとおりに機能することは保証できません。
なぜこのレッスンは廃止されたのでしょうか?
大英博物館は、自身のコレクションデータベースについて、永続的で、かつ、信頼できるアクセス方法の維持管理を行わなくなりました。レッスン内のSPARQLの文法とコマンドは正しいものではあるのですが、実習でアクセスしようとするURLがもはや信頼できるものになっていないためです。
[訳注:上記の通り、the Programming Historianの原著ページでは、すでにこのレッスン内容は廃止、更新停止の決定が下されています。しかし、内容として学ぶべきものがあると考え訳出しました。実習でアクセスする際はご注意ください。]
レッスンの目標
このレッスンでは、多くの文化機関がグラフデータベースを取り入れている理由と、SPARQLと呼ばれるクエリ言語を通じて、研究者たちがこれらのデータにアクセスする方法について解説しています。
目次
グラフデータベース、RDF、そしてリンクト・オープン・データ
現在、多くの文化機関が自分たちの収集情報をウェブ・アプリケーション・プログラミング・インターフェース(Web API)からアクセスできるようにしています。これらのAPIは、個別の記録に機械可読な方法でアクセスできる強力な方法です。しかし、あらかじめ定められた一連のクエリで動作するように作られているため、文化遺産データとしては理想的でありません。例えば、ある美術館に寄贈者、アーティスト名、作品名、展示会名、出所に関する情報があったとします。しかし、Web APIで提供できるのはモノとしての検索項目だけあって、そのために、寄贈者、アーティスト、出所等のデータを検索するのが困難あるいは不可能になってしまうかもしれません。この構造では、ある特定のモノに関する情報を探す場合には都合がよいのですが、データセットにも収録されることになったすべてのアーティストや寄贈者に関する情報を集約することが難しいものとなります。
RDFデータベースは、個々のオブジェクトに結びついた、人や場所、出来事、概念といった多数のエンティティの間の複雑な関連性を表すのに最適です。これらのデータベースは、情報をグラフあるいはネットワークとして構造化しているため、大抵は「グラフ」データベースと呼ばれており、リソースのセットあるいはノードが、各リソースの関連性を記述したエッジを介して結びついています。
RDFデータベースは、URL(ウェブリンク)の利用が可能であるため、オンラインで他のデータベースとリンクすることが可能です。そのために「リンクト・オープン・データ(Linked Open Data)」と呼ばれます。大英博物館、Europeana、スミソニアン・アメリカ美術館およびYale Center for British Artなどの主要なアートコレクション機関は、そのコレクションデータをLODとして公開しています。Getty Vocabulary Programも、信頼できるデータベース上で、地名、アート作品や建築物に関する記述、アーティストの情報をLODとして公開しています。
SPARQLは、これらのデータベースに対して問い合わせ(クエリ)をする際に用いる言語です。この言語は、ユーザーがデータにもたらす視点を前提としないため、特に強力です。資料に関するクエリと寄贈者に関するクエリは、基本的にそのようなデータベースと同じです。残念なことに、SPARQLに関するチュートリアルの多くは、文化遺産機関が公開しているような、より複雑なデータセットとは違い、非常に簡略化されたデータモデルを使用しています。このチュートリアルでは、人文系研究者がインターネット上で普段見かけるようなデータセットを使って、SPARQLの集中講座を提供します。特に、大英博物館のLODコレクションに対するクエリの仕方を学んでいきます。
RDFの概要
RDFは、以下の例のような、主語、述語、目的語という3つのパートから構成された「文(statement)」で情報を表現します。
<The Nightwatch> <was created by> <Rembrandt van Rijn> .
(通常の文のように、それぞれの末尾にピリオドがあることに注意します。)
ここでは、主語<The Nightwatch>と目的語<Rembrandt van Rijn>は、グラフにおける2つのノードであり、述語<was created by>はこれら語の間の関係を定義します。(技術的には、<was created by>は、別のクエリでは目的語や主語として扱うことができますが、このあたりは本チュートリアルの範囲外です。)
例として作成したRDFデータベースでは、次のような相互に関係する複数のステートメントが含まれる場合があります。
...
<The Nightwatch> <was created by> <Rembrandt van Rijn> .
<The Nightwatch> <was created in> <1642> .
<The Nightwatch> <has medium> <oil on canvas> . <Rembrandt van Rijn> <was born in> <1606> .
<Rembrandt van Rijn> <has nationality> <Dutch> .
<Johannes Vermeer> <has nationality> <Dutch> .
<Woman with a Balance> <was created by> <Johannes Vermeer> .
<Woman with a Balance> <has medium> <oil on canvas> .
...
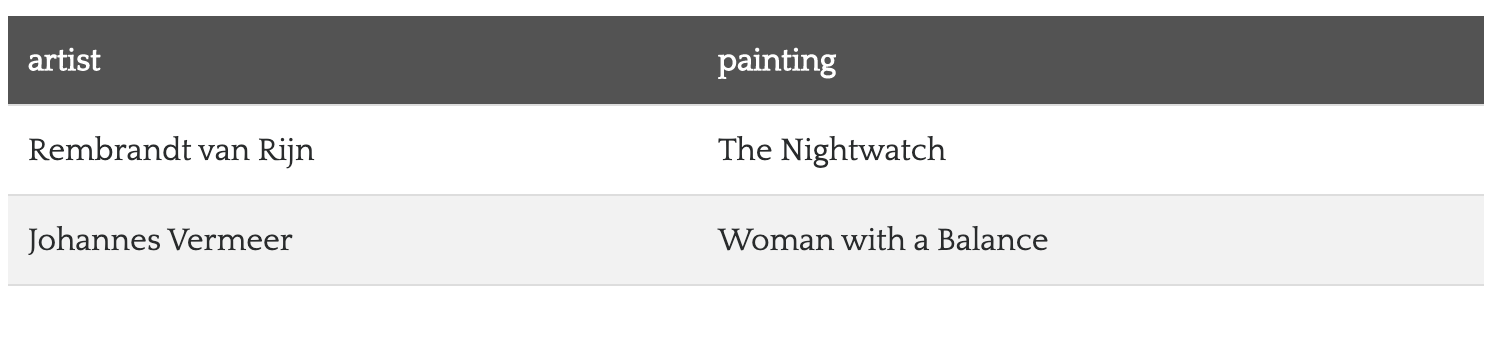
これらのステートメントをネットワークグラフ内のノードやエッジとして可視化したとしたら、このように見えるはずです。
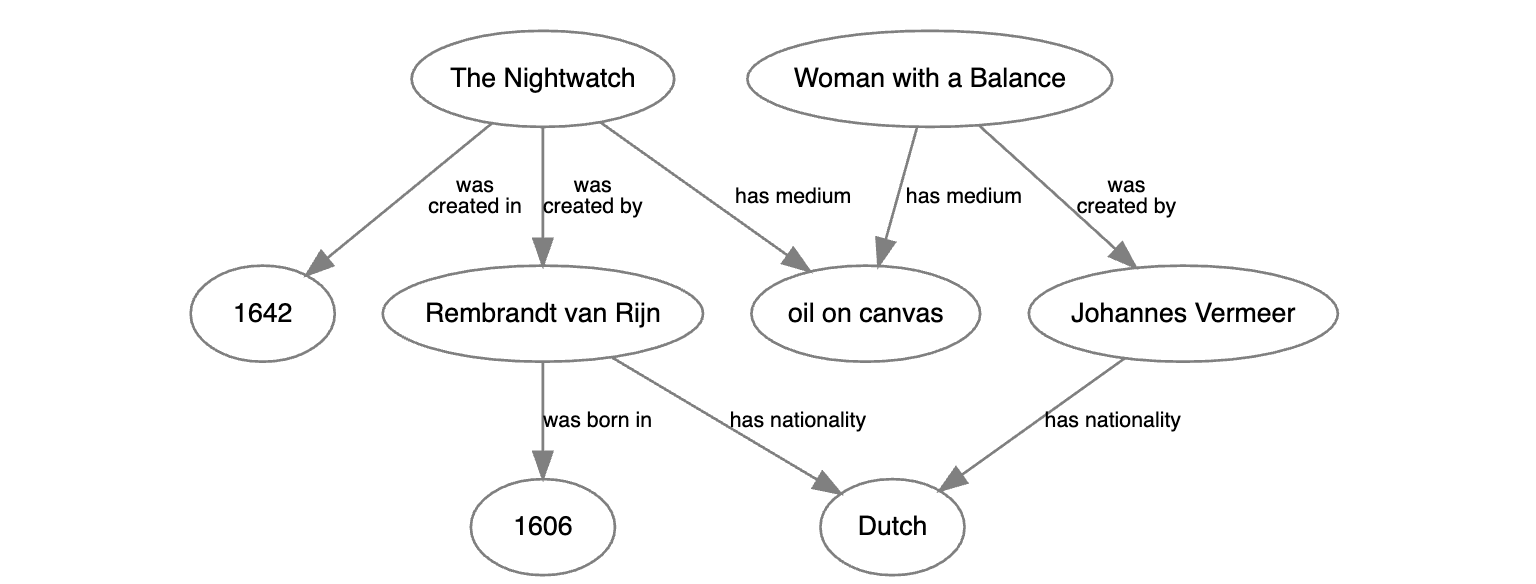
RDFのネットワーク可視化状態を上記に示しました。矢印は、述語の「方向」を示します。例えば、「天秤を持つ女(Woman with a Balance)は、フェルメール(Vermeer)によって作られた(was created by)」となり、その逆ではありません。
従来のリレーショナルデータベースでは、芸術作品に関する属性(情報)と、そのアーティストに関する属性(情報)を、別の表に分割してしまうことがありました。RDFあるいはグラフデータベースでは、これらのデータの点すべてが連結するグラフにつながっており、これによって、ユーザーには最大限柔軟な検索が可能となります。
SPARQLを使ったRDFの検索方法
SPARQLは、複雑に連結しているグラフデータを、Excelのようなプログラムで開くことができる行や列のある、正規化された表形式データへと変換してくれたり、plot.lyやPalladioなどの可視化ソフトにインポートできるようにしてくれます。
SPARQLクエリは、Mad Lib(文中に空白のある文章のセット)として考えるとよいです。グラフデータベースは、このクエリを受け取り、それらの空白を正しく埋めるすべてのステートメントを見つけ、そして一致する値を表形式で返します。次のSPARQLクエリを考えてみましょう。
SELECT ?painting
WHERE {
?painting <has medium> <oil on canvas> .
}
このクエリ中の?paintingは、データベースが返すノード(複数のこともある)を表します。このクエリを受け取ると、すぐにデータベースが適切にRDFステートメント<has medium> <oil on canvas>.を完成させる?paintingのすべての値を検索します。
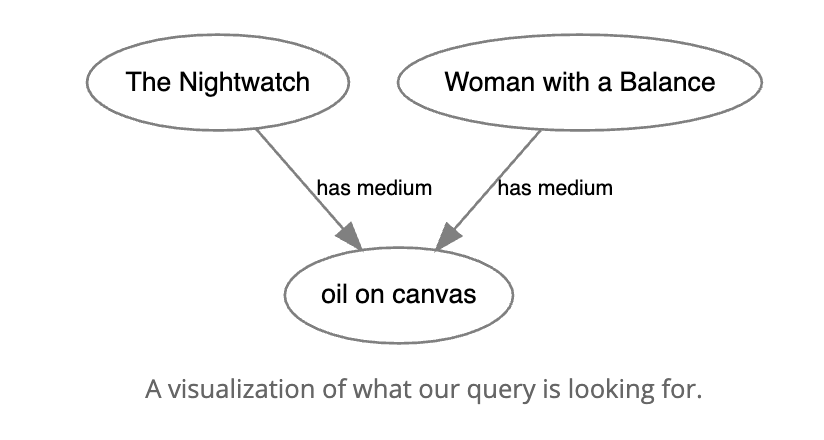
データベース全体に対してクエリを実行すると、この文に一致する主語、述語、および目的語が検索され、残りのデータは除外されます。
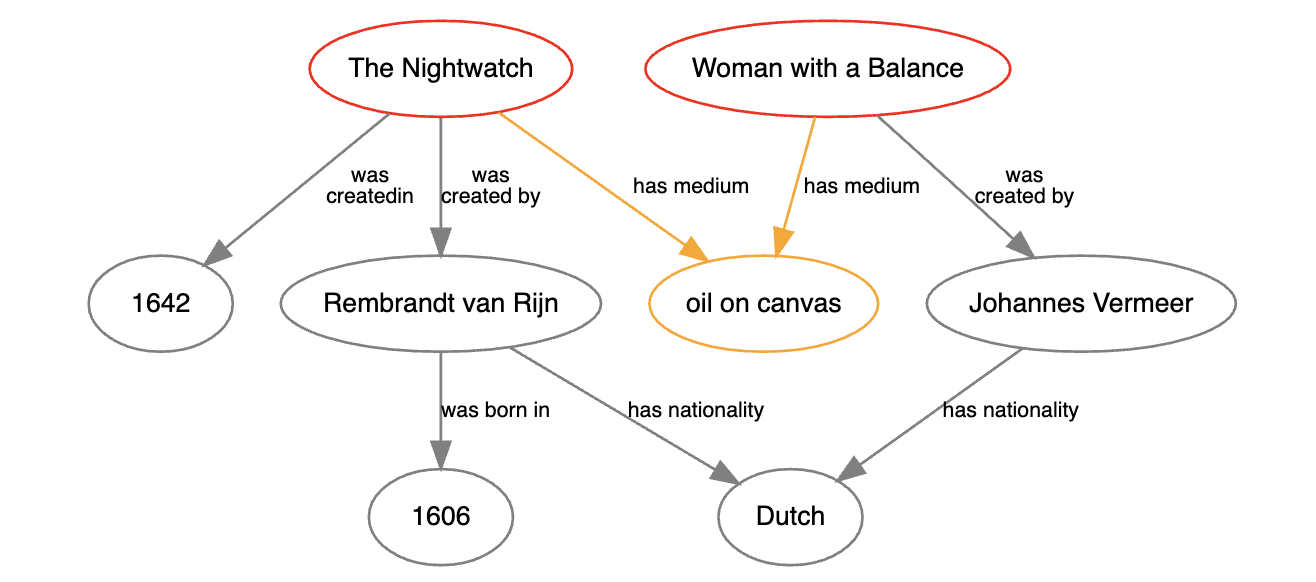
その結果は、次のような表になります。

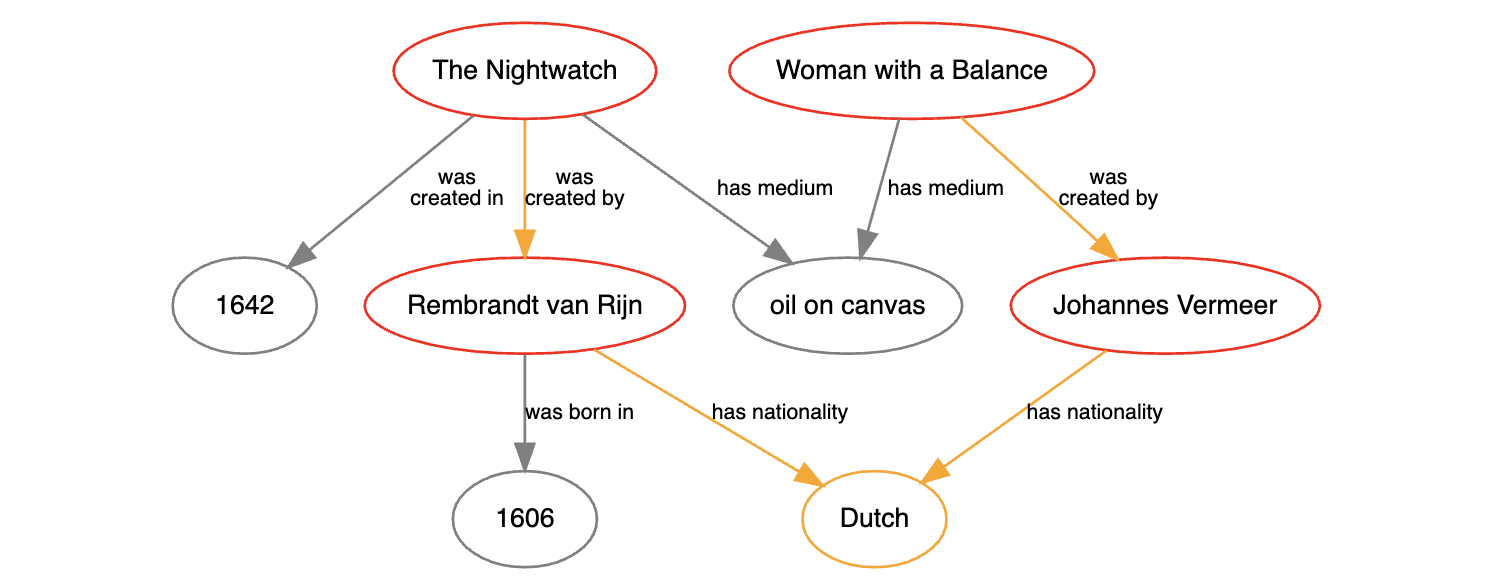
RDFとSPARQLが強力なのは、一度に多くの変数を参照する複雑なクエリを作成できるからです。例えば、オランダ人の画家によって描かれた絵画を、先ほどのRDFデータベースで検索すると、次のようなクエリになります。
SELECT ?artist ?painting
WHERE {
?artist <has nationality> <Dutch> .
?painting <was created by> ?artist .
}
URIとリテラル
ここまで、読みやすいテキストを使用したRDFの簡単な表現を見てきました。ただし、RDFは主にURI(Uniform Resource Identifier)として保存され、概念上のエンティティを平易な英語(あるいは他の言語でも!)ラベルから引き離すものです。(URL、つまりUniform Resource Locatorとは、ウェブ上でアクセス可能なリソースのためのURIだということに注意してください。)実際のRDFでは、以下のステートメントは
<The Nightwatch> <was created by> <Rembrandt van Rijn> .
次のようなものになりそうです。
<http://data.rijksmuseum.nl/item/8909812347> <http://purl.org/dc/terms/creator> <http://dbpedia.org/resource/Rembrandt>.
オランダのアムステルダム国立美術館は、(まだ)自身のリンクト・オープン・データ(Linked Open Data)サイトを構築していないため、このクエリにあるURIはデモです。
これらのURIが示す情報の、人間にとってより読みやすいバージョンを入手するために、より多くのRDFステートメントを集めるということを実際に行っています。このステートメントにある述語でさえ、独自のリテラルなラベルを持っています:
<http://data.rijksmuseum.nl/item/8909812347>
<http://purl.org/dc/terms/title> “The Nightwatch” .
<http://purl.org/dc/terms/creator>
<http://www.w3.org/1999/02/22-rdf-syntax-ns#label> “was
created by” .
<http://dbpedia.org/resource/Rembrandt>
<http://xmlns.com/foaf/0.1/name> “Rembrandt van Rijn” .
<>で囲まれているクエリ内のURIとは異なり、これらのステートメントの「目的語」は、「リテラル」と呼ばれる引用符(””)で囲まれた文字列であることに気づくでしょう。リテラルは、参照ではなく値そのものを表すという点で、URIとは異なります。例えば、<http://dbpedia.org/resource/Rembrandt>は、任意の数の他のステートメント(生年月日、学生、家族など)を参照する/参照されることのできるエンティティを表します。一方で、”Rembrandt van Rijn”という文字列は、それ自体を表すのみです。リテラルは、グラフにある別のノードを指し示すことはなく、RDFステートメントの目的語しかなりえません。RDFのその他のリテラル値には日付と数が含まれます。
purl.org,w3.orgおよびxmlns.comのようなドメイン名を持つステートメントの「述語」をみてください。これらは、「タイトル」、「ラベル」、「作成者」、あるいは「名前」のような情報のビット間の関連を記述する方法を標準化するのに役立つオントロジーの提供者の例です。皆さんがRDFあるいはLODをより使うようになれば、これらの提供者を見ることも増えていくでしょう。
URIは、SPARQLクエリを作成するときに扱いにくくなる可能性があるため、「接頭辞」(プレフィックス)を使用します。これは、長いURI全体の入力をスキップできるショートカットです。たとえば、『夜警(Nightwatch)』のタイトルを取得するための述語<http://purl.org/dc/terms/title>を覚えていますか? プレフィックスを使うことで、purl.orgの述語を使う必要があるときはdct:titleと入力するだけで済むのです。dct:はhttp://purl.org/dc/terms/を表し、titleをこのリンクの最後に貼り付けるだけです。
たとえば、こちらの接頭辞PREFIX rkm: <http://data.rijksmuseum.nl/>を利用して、先ほどのSPARQLクエリにの頭に追加すると、<http://data.rijksmuseum.nl/item/8909812347>の代わりにrkm:item/8909812347となります。
接頭辞には好きな略語を何でも任意に割り当てることができ、別のエンドポイントでは、同じ名前空欄に対して少し異なる接頭辞が使われている可能性があるということを覚えておきましょう(例えば、http://purl.org/dc/terms/におけるdctとdctermsのようにです)。
用語の確認
- SPARQL – プロトコルおよびRDFクエリ言語- RDFグラフデータベースに対してクエリを発行する際に用いる言語
- RDF – Resource Description Framework– データを表でなく、グラフあるいは連結した文のネットワークとして構築するための手法
- LOD – Linked Open Data – LODは、開発者が確実に参照できるような方法で専用のURIを使用してオンライン公開されたRDFデータです。
- ステートメント – 「トリプル」とも呼ばれることもあり、RDFステートメントは、主語、述語、目的語を含むナレッジから構成されています。
- URI – Uniform Resource Identifier- リソースを識別するための文字列。RDFステートメントはURIを使って各種リソースへリンクします。URL、つまりは、統一資源位置指定子はURIの一種で、ウェブ上のリソースを指します。
- リテラル – RDFステートメント中の目的語には、URIで別のリソースを参照するのでなく、文字(“Rembrandt van Rijn”)、数字(5)あるいは日付1606-06-15)といった値を表示させるものがあります。これらたリテラルとして知られているものです。
- 接頭辞 – SPARQLクエリを簡略化するために、ユーザーは、完全なURIに代わる略語として接頭辞を指定することができます。これらの略語、あるいはQNamesは、XML名前空間でも用いられます。
実際のクエリ
一つのオブジェクトのすべてのステートメント
大英博物館のSPARQLエンドポイントを使って、初めてのクエリ作成に挑戦してみましょう。SPARQLエンドポイントは、SPARQLクエリを受け取り、結果を返してくれるウェブアドレスです。大英博物館のエンドポイントは、数あるエンドポイントの事例の一つとして、ウェブブラウザでアクセスすると、クエリを記入するためのテキストボックスが表示されます。

新しいRDFデータベースの検索を始める際は、ある一つのサンプルオブジェクトをもとに、その関係性を調べるとよいでしょう。
(以下の各クエリについては、下にある「クエリを実行(“Run query”)」[訳注:クエリを実行をクリックしても、現在はつながりませんので、この翻訳記事からはリンクを外しています。]のリンクをクリックすることで結果を見ることができます。そうすると、そのまま実行するか、結果を求める前に変更することができます。実行前にクエリを編集する際は、「推測を含む」ボックスにチェックを入れないようにすることを覚えておきましょう。
SELECT
?p ?o
WHERE
{
<http://collection.britishmuseum.org/id/object/PPA82633> ?p ?o .
}
クエリの実行
SELECT ?p ?oと書くことで、データベースに対し、WHERE {}コマンド内で記述されている通りの?pおよび?oの値を返すように求めます。このクエリは、事例として挙げた芸術作品<http://collection.britishmuseum.org/id/object/PPA82633>が主語となっているすべてのステートメントを返してきます。?pは、WHERE {}コマンドにあるRDFステートメントの中央に位置し、このステートメントにマッチする述語を返します。また、最後の位置にある?oはすべての目的語を返してくれます。ここでは、?pと?oと名前を付けていますが、以下で分かるように、変数の名前は何でも好きなものにすることができます。実際に、後で出てくる複雑なクエリでは、変数にわかりやすい名前を付けると便利ですよ!
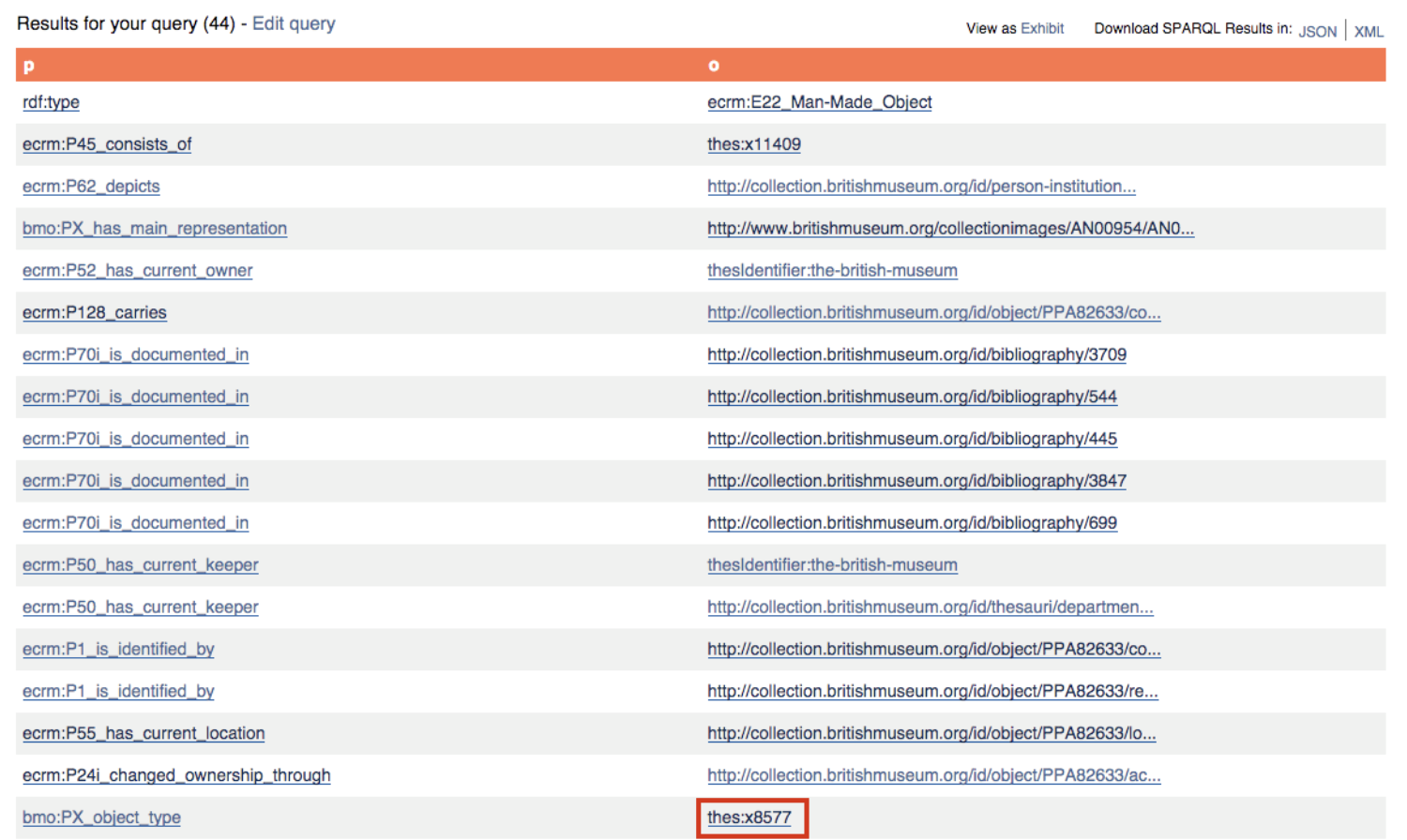
注意:このレッスンを読んだときに、大英博物館がSPARQLエンドポイントをどのように設定したかによって、URLの「接頭辞付き」バージョン(例えばthes:8577)ではなく、フルバージョンのhttp://collection.britishmuseum.org/id/thesauri/x8577が表示される可能性があります。上記の接頭辞に関する説明で述べたように、これはまだ同じURIを表現しています。
大英博物館エンドポイントは、それ自体がRDFのノードである各変数に対し、ハイパーリンクで、検索結果の表を表示させます。そのため、これらのリンクのどれか一つをクリックすることで、新たに選択されたノードに対応した述語と目的語すべてを見ることができます。大英博物館は、クエリにあるSPARQLの幅広い接頭辞を自動で含めているため、簡略化されたバージョンで表示される多数のハイパーリンクを目にすることになる、ということを覚えておきましょう。そして、マウスオーバーすると、ブラウザで正規バージョンのURIが表示されます。
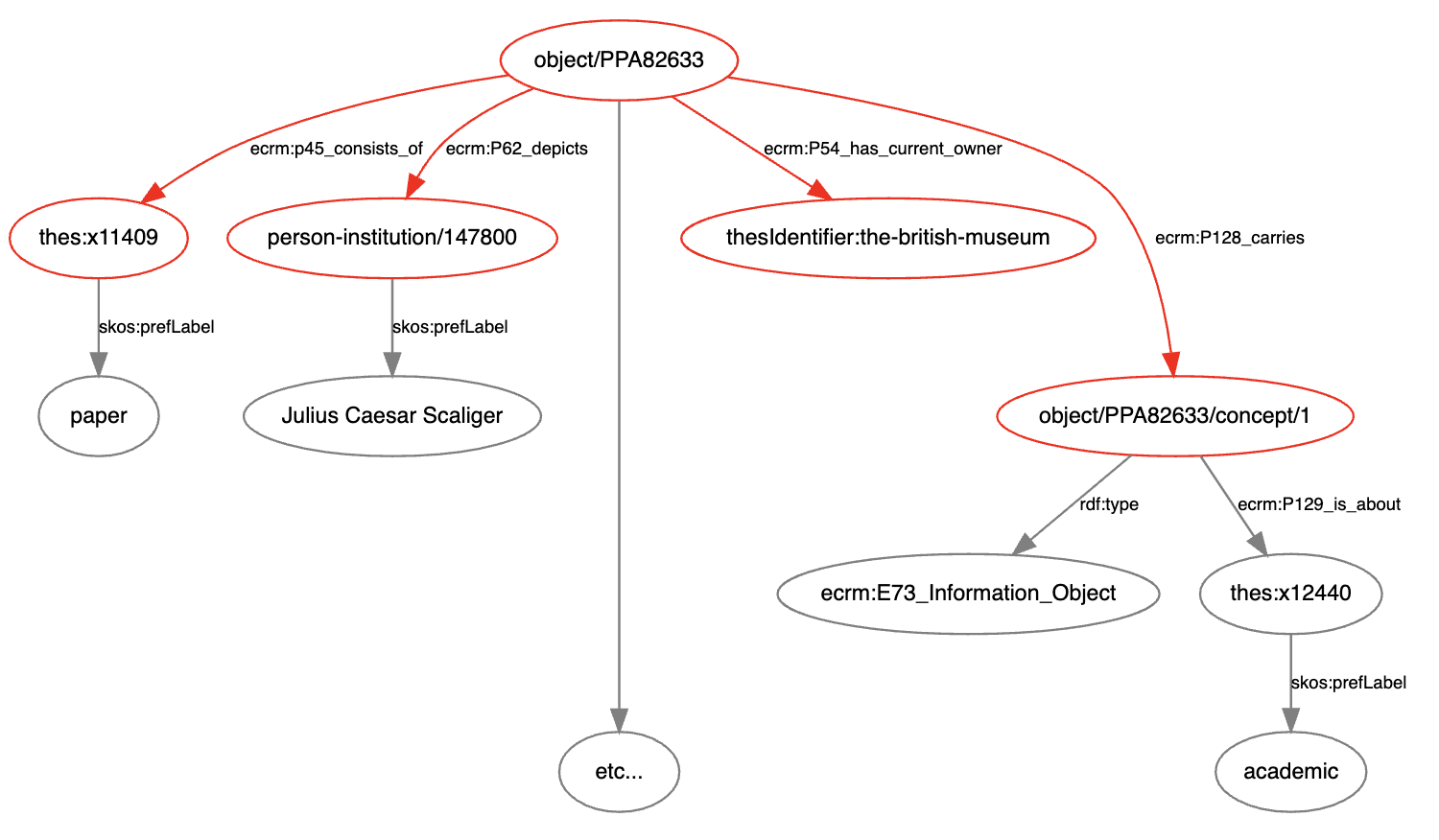
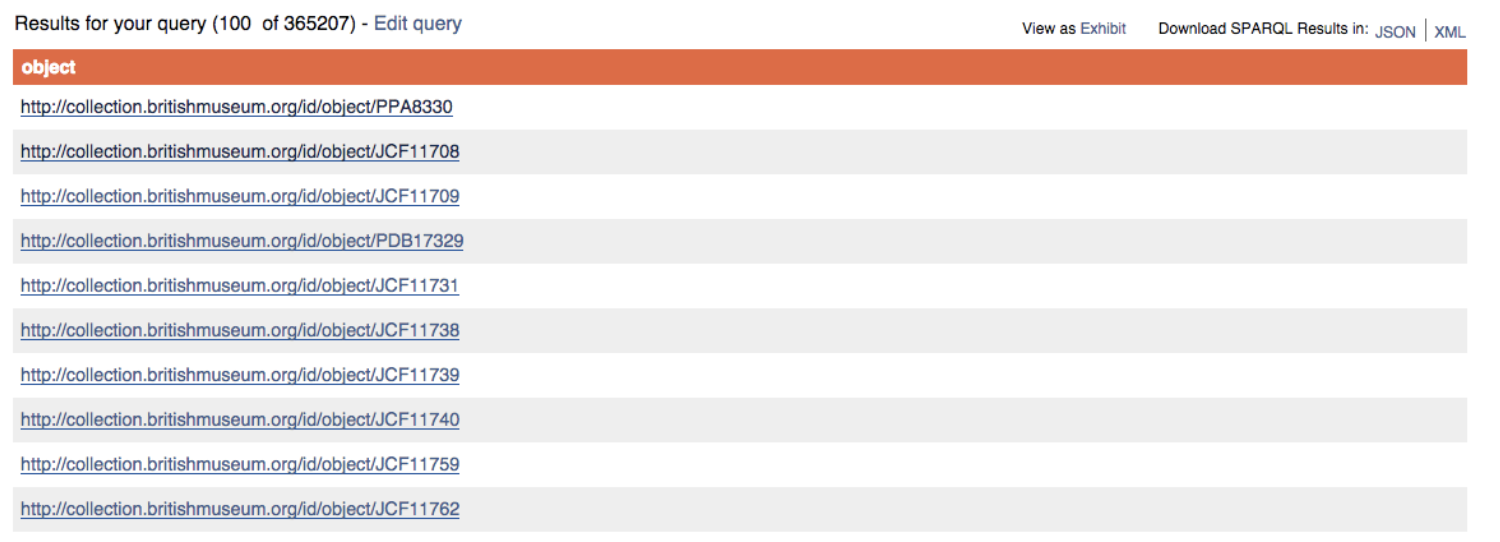
オブジェクトタイプの情報がどのように保存されているかを見てみましょう。述語<bmo:PX_object_type>(上記の図中でハイライトされているものです)を探して、thes:x8577のリンクをクリックし、“print”とオブジェクトタイプに書かれているノードへと遷移します。
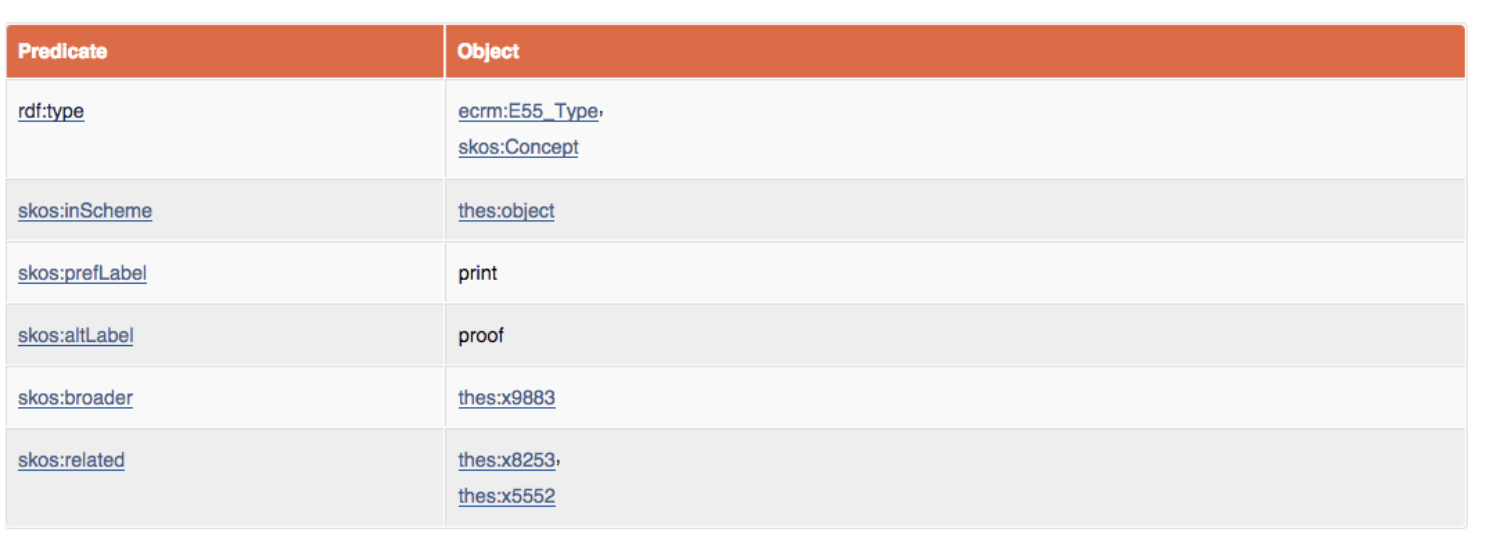
ここから、このノードがどのようなプレーンテキストのラベルを持ち、また、データベース内の関連する作品タイプのノードと結びついているかが分かるでしょう。
複雑なクエリ
“print”のラベルを持つ同じタイプで別の目的語を探すには、次のクエリで可能です。
PREFIX bmo:
<http://www.researchspace.org/ontology/>
PREFIX skos:
<http://www.w3.org/2004/02/skos/core#
>SELECT ?object
WHERE {
# 特定の「オブジェクトタイプ」を持つすべての “?object” の値を検索
?object bmo:PX_object_type ?object_type .
# そのオブジェクトタイプはラベル”print”をもつこと
?object_type skos:prefLabel “print” .
}
LIMIT
10
クエリの実行/ ユーザの作成したクエリを見る
“print”が「リテラル」であることから、クエリではその語を引用符(””)で囲みました。SPARQLクエリがリテラルを含む場合、データベースはそのデータ値との「完全一致のみ」を返すことになります。
また、?object_typeがSELECTコマンドには存在しないため、検索結果テーブルには表示されないことに注意しましょう。とはいえ、?objectからラベル“print”を結び付けるため、このクエリを構成する際は重要です。
FILTERコマンド
先ほどのクエリでは、テキストラベル”print”と完全一致するオブジェクトタイプのものを検索しました。しかし、日付など、ある一定の範囲にあるリテラル値と一致させたいということがよくあります。その際は、FILTERコマンドを使うことになります。
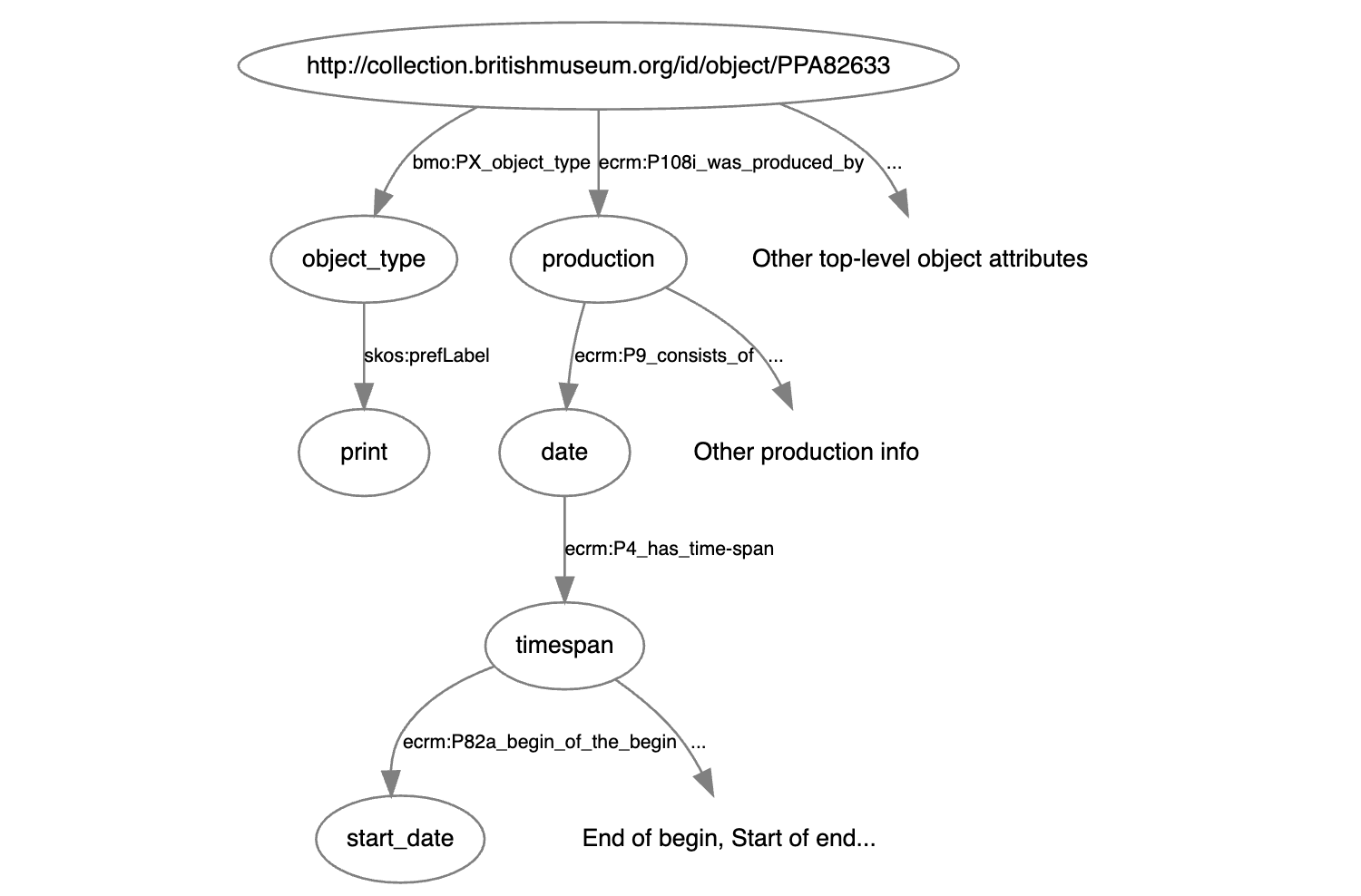
例えば、1580年から1600年までの間に作成された、大英博物館にあるすべての印刷物に関するURIを探すには、まず初めに、目的語のノードと関連のある日付の情報が、データベースのどこに保存されているかを見つける必要があります。先ほど一つのリンクをたどってオブジェクトタイプを割り出したのと同じように、複数のノードをたどりながら任意の目的語と関連する作成日を探します。
PREFIX bmo: <http://www.researchspace.org/ontology/>
PREFIX skos:<http://www.w3.org/2004/02/skos/core#>
PREFIX ecrm: <http://www.cidoc-crm.org/cidoc-crm/>
PREFIX
xsd: <http://www.w3.org/2001/XMLSchema#>#>
オブジェクトへのリンクと作成日を返す
SELECT ?object ?date
WHERE {
# 前のコマンドを使用して、”print”タイプのオブジェクトのみを検索します。
?object bmo:PX_object_type ?object_type .
?object_type skos:prefLabel “print”
.
# 資料に関連付けられた作成日を見つけるために、いくつかのノードをリンクする必要があります
?object ecrm:P108i_was_produced_by
?production .
?production ecrm:P9_consists_of ?date_node .
?date_node ecrm:P4_has_time-span ?timespan .
?timespan ecrm:P82a_begin_of_the_begin ?date
.
# ご覧のとおり、日付ノードに到達するにはかなりの数のドットを接続する必要があります! これで結果をフィルタリングできます。日付でフィルタリングするため、日付文字列の後に^^ xsd:dateタグを添付する必要があります。このタグは、文字列「1580-01-01」を1580年1月1日として解釈するようデータベースに指示します。
FILTER(?date >=
“1580-01-01″^^xsd:date &&
?date <= “1600-01-01″^^xsd:date)
}
クエリの実行
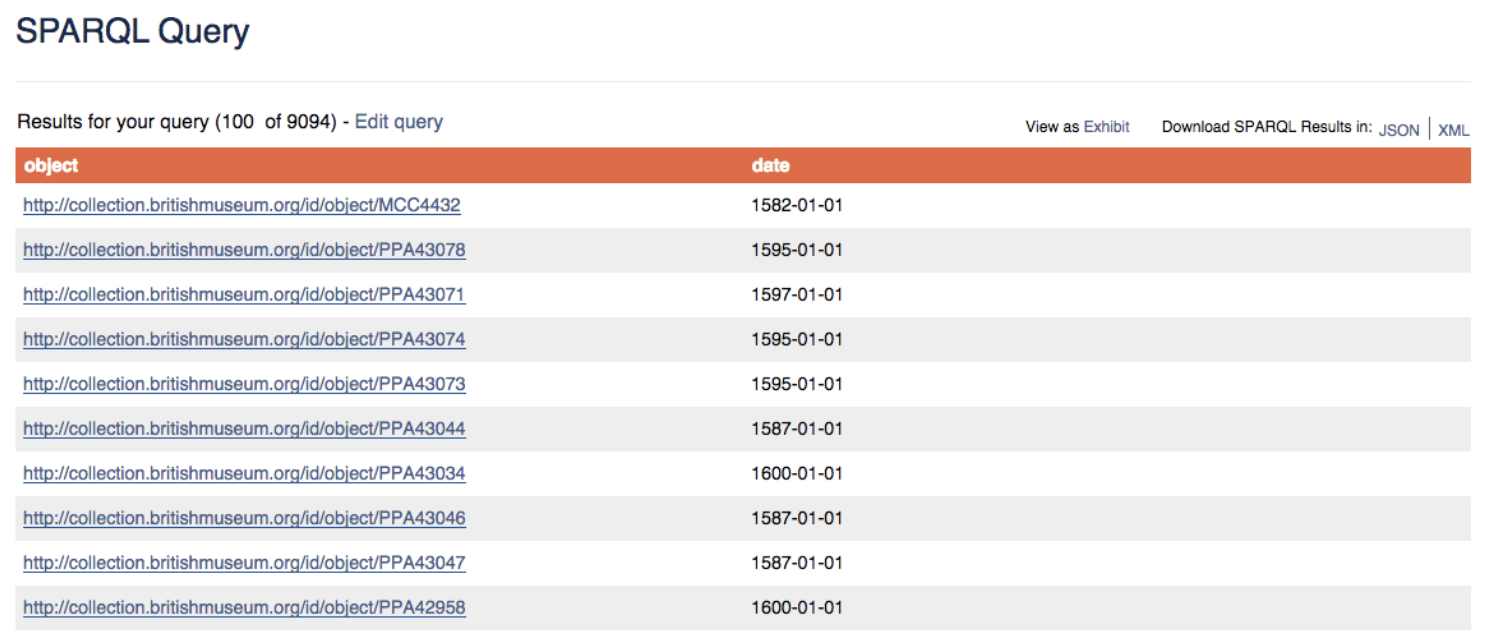
アグリゲーション
これまでは、オブジェクトの一覧を返す際に、SELECTコマンドのみを使用してきました。SPARQLはグルーピングやカウント、ソートなど、より高度な分析を行うことも可能です。
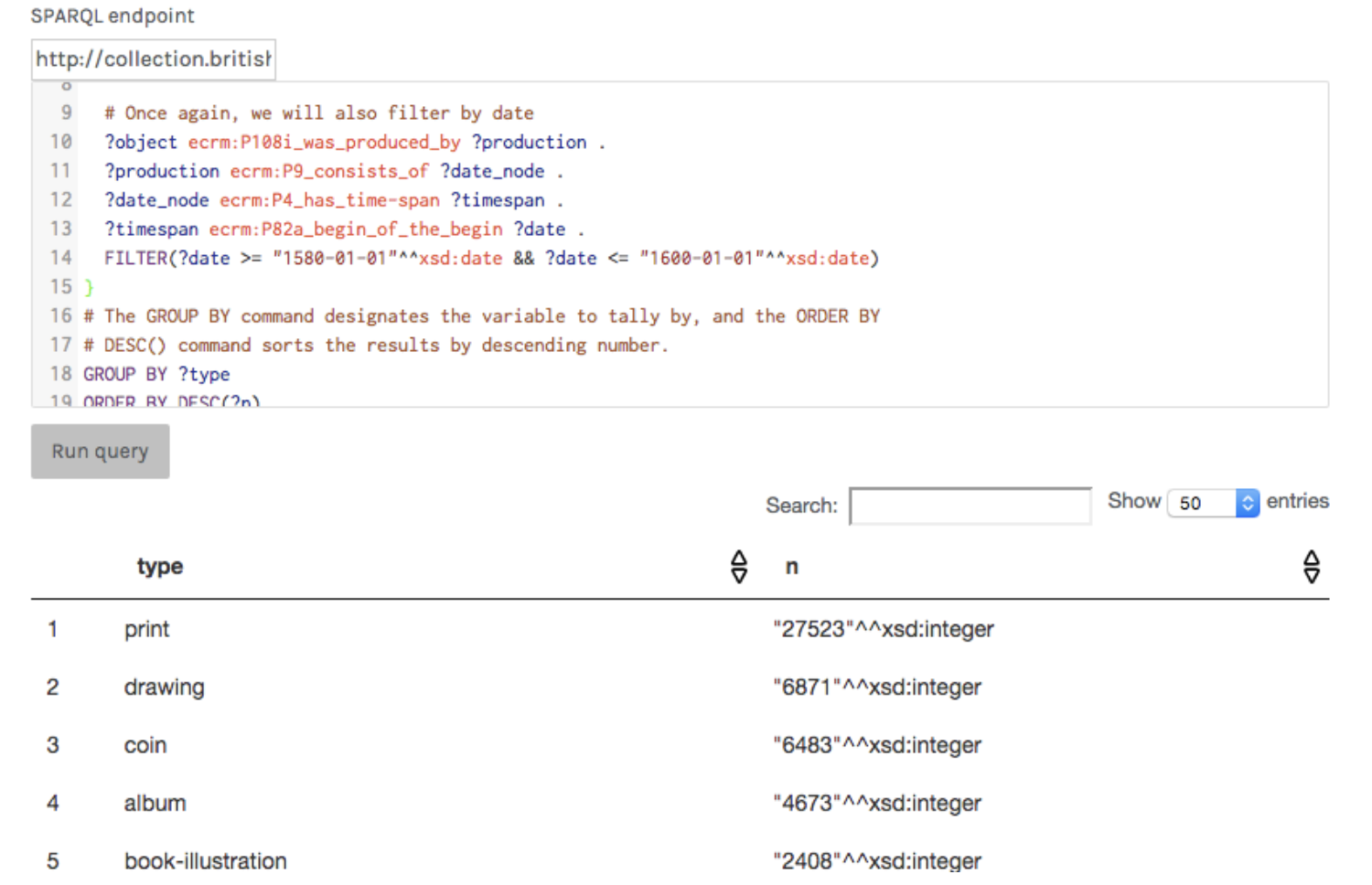
ここでも1580年から1600年までの資料を見ていきたいと思いますが、大英博物館がタイプ別にどのくらいの資料を所蔵しているかを見たいと思います。オブジェクトタイプに”print”とある資料だけに限定するのでなく、COUNTを使って資料種類別に検索結果をカウントしてみましょう。
PREFIX bmo: <http://www.researchspace.org/ontology/>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX ecrm: <http://www.cidoc-crm.org/cidoc-crm/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?type (COUNT(?type) as ?n)
WHERE {
# ?object_typeの変数を指定する必要がありますが、今回は”print”と一致させる必要はありません。
?object bmo:PX_object_type ?object_type .
?object_type skos:prefLabel ?type .
# もう一度、日付でフィルタをかけます
?object ecrm:P108i_was_produced_by ?production .
?production ecrm:P9_consists_of ?date_node .
?date_node ecrm:P4_has_time-span ?timespan .
?timespan ecrm:P82a_begin_of_the_begin ?date .
FILTER(?date >= "1580-01-01"^^xsd:date &&
?date <= "1600-01-01"^^xsd:date)
}
# GROUP BYコマンドは、集計する変数を指定します。ORDER BY DESC()コマンドは、結果を降順でソートします。
GROUP BY ?type
ORDER BY DESC(?n)
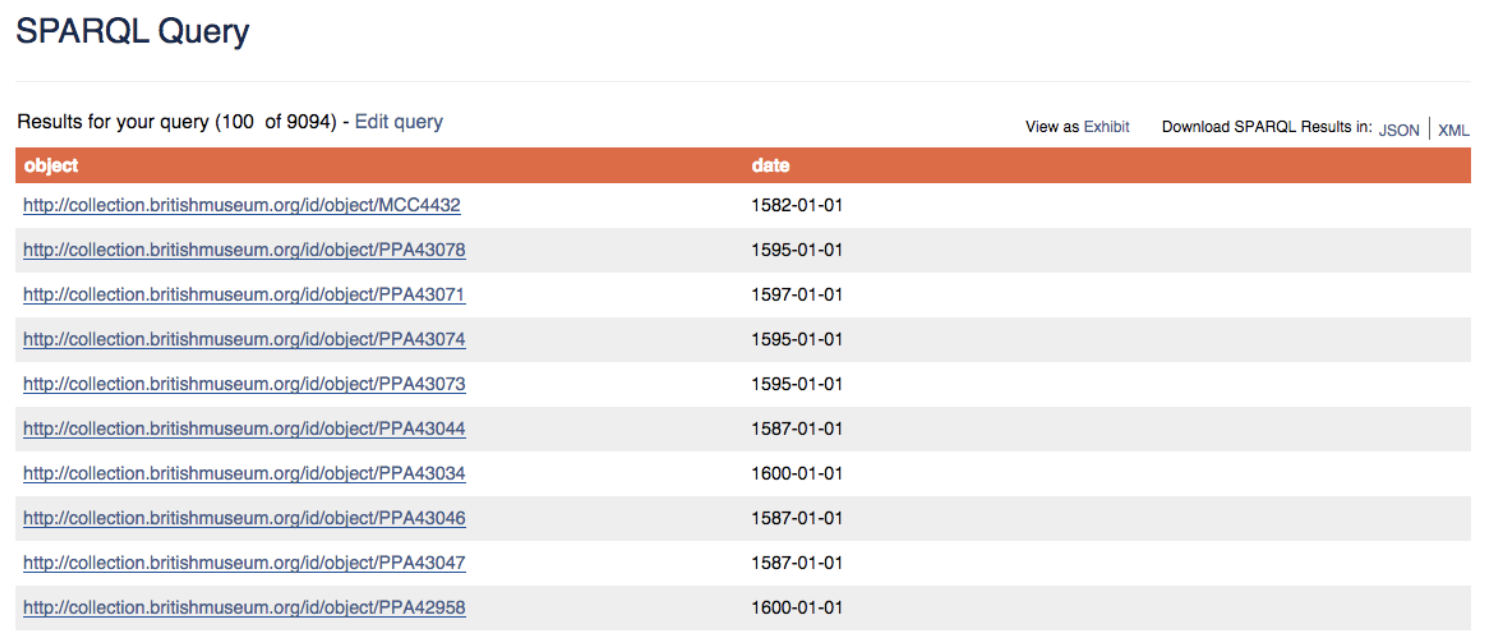
クエリの実行
複数のSPARQLエンドポイントのリンク設定
2018年6月13日付け注記:残念なことに、Europeanaは、SERVICEクエリを使った外部SPARQLエンドポイントへのリンク機能を削除してしまったため、この章のクエリは、もう実行できなくなっています。以下のテキストは、参照目的で残しているものであり、もしEuropeanaがSERVICEクエリの利用を再開すれば更新される可能性があります。
ここまで、一つのデータセット内のパターンを検索するクエリを扱ってきました。LOD支持者の思い描く理想的な世界では、複数のデータベースを相互リンクして、さまざまな場所に存在する知識に基づいた非常に複雑なクエリを実行できるようになります。一方で、これは言うが易しであり、(大英博物館のものをふくめ)多くのエンドポイントはその外側へと参照することができません。
ただし、Europeanaのものだけが異なります。Europeanaは、データベース内の資料と、DBPediaやVIAFにある個人のレコードやGeoNamesにある場所の情報、Getty Art & Architecture thesaurusにある概念との間でリンクさせました。それにより、SPARQLを使うことでデータベースに「友達に電話して」と指示を出して、外部のデータセットでクエリの一部を実行するSERVICEステートメントを挿入し、その結果を利用して、ローカルなデータセットでクエリを完了させることができるようになりました。このレッスンでは、EuropeanaとDBpediaのデータモデルについて詳しく説明しますが、次のクエリではSELECTステートメントがどのような機能を持つのかを説明します。ご自身でクエリのテキスト文をEuropeanaのSPARQLエンドポイントへコピーペーストして実行することも可能です。
PREFIX edm: <http://www.europeana.eu/schemas/edm/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX dbo: <http://dbpedia.org/ontology/>
PREFIX dbr: <http://dbpedia.org/resource/>
PREFIX rdaGr2: <http://rdvocab.info/ElementsGr2/>
# ?dutch_cityで生まれた?agentで、何らかの?propertyで関連数すべての?objectを検索します。
SELECT ?object ?property ?agent ?dutch_city
WHERE {
?proxy ?property ?agent .
?proxy ore:proxyFor ?object .
?agent rdf:type edm:Agent .
?agent rdaGr2:placeOfBirth ?dutch_city .
# ?dutch_cityは、DBpedia内で”Netherlands”を持つ広い国として定義されています。SERVICEステートメントは、http://dbpdeia.org/sparqlに対して、どの都市に”Netrherlands”という国の情報があるかを問いあわせます。その後、そのサブクエリへの回答を使用して、Europeanaのデータベース内の資料に関する元のクエリを終了させます。
SERVICE <http://dbpedia.org/sparql> {
?dutch_city dbo:country dbr:Netherlands .
}
}
# このクエリは多くの資料を返す可能性があるため、検索を高速化するために最初の100件をリクエストしてみましょう。
LIMIT 100
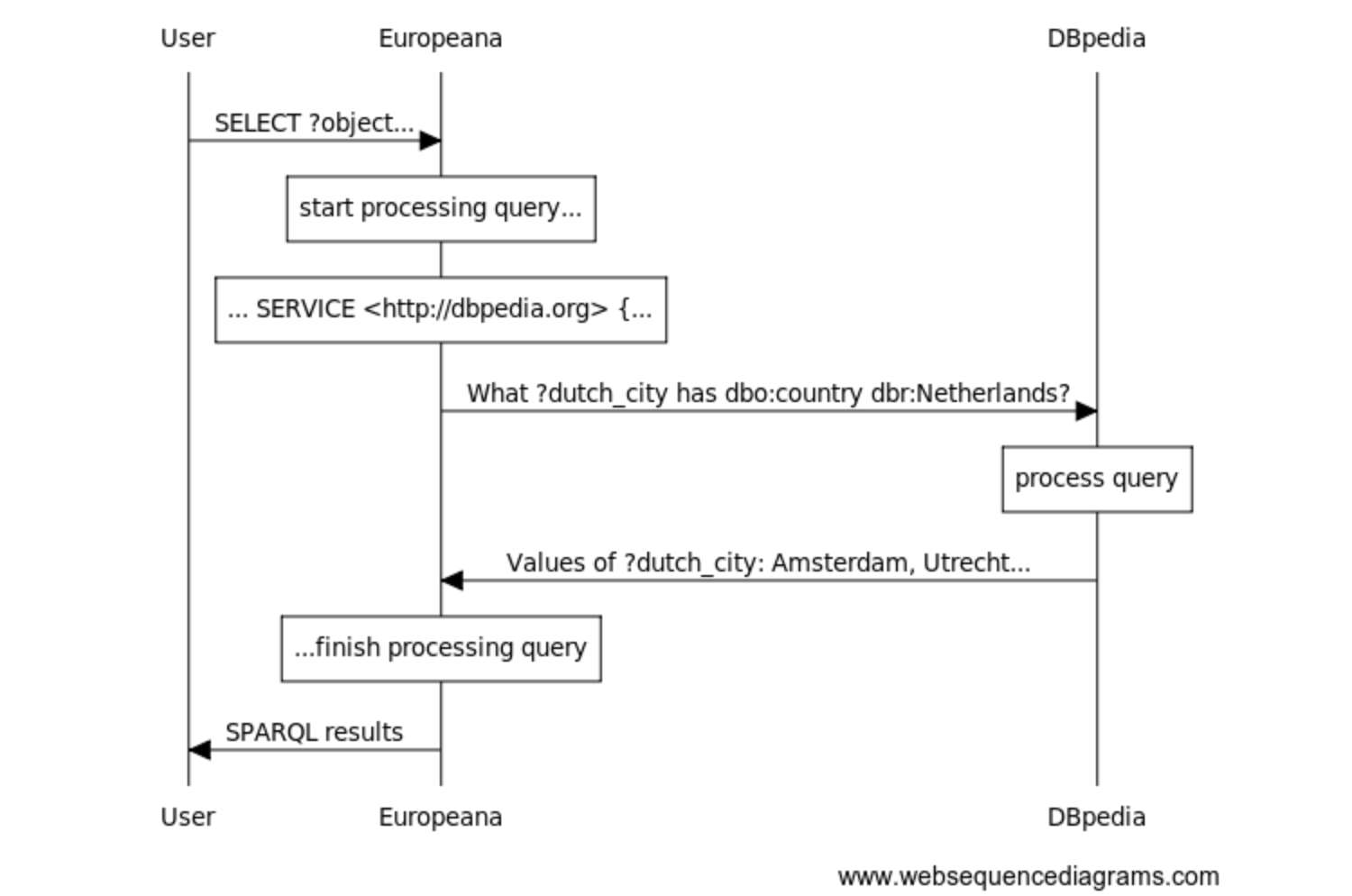
このように相互にリンクしたクエリを問いあわせることで、Europeanaが自分で維持管理する必要のない地理学に関する情報(上記の例ではオランダの都市はどこか)に基づいた資料についてもEuropeanaのみに問い合わせを行うことができるわけです。今後、さらに文化情報を扱ったLODが、Getty’s Union List of Artist Names(ゲティ研究所)のような影響力のあるデータベースにリンクして、例えば大英博物館が伝記資料をゲッティ研究所のより完成されたリソースにアウトソースできるようになればいいですね。
SPARQLの検索結果の使い方
クエリを作成して実行して…、で、この結果をどうしたらいいのでしょう?大英博物館のような多くのエンドポイントでは、人間が読むことのできる結果を返すウェブベースのブラウザを提供してくれています。一方で、SPARQLエンドポイントは、別のプログラムで使うような構造化データを返すようにも設計されています。
結果をCSV形式でエクスポートする
大英博物館のエンドポイントの検索結果ページの右上角に、JSONとXML形式データでダウンロードできるリンクがあるのが分かります。その他のエンドポイントではCSVやTSV形式でダウンロードできるオプションがある場合もありますが、このオプションはいつも利用できるとは限りません。SPARQLエンドポイントから出力されたJSONやXMLは、SELECTステートメントから返された値だけでなく、変数のタイプと言語に関する追加のメタデータも含まれます。
Beautiful Soup (Programming Historianのレッスンを参照)やOpen Refineのようなツールで、出力されたXMLデータを解析することができます。SPARQLエンドポイントから得られたJSONデータをすばやく表形式に変換するには、無料のコマンドラインユーティリティjqがお勧めです。(コマンドラインプログラムを使ったチュートリアルについては、“Introduction to the Bash Command Line”をご覧ください)。以下のコマンドは、特別なJSON RDF形式をCSVファイル形式に変換するもので、これにより、さらに解析したり可視化できる自分のお気に入りのプログラムに読み込ませることができます。
jq -r ‘.head.vars as $fields | ($fields | @csv),
(.results.bindings[] | [.[$fields[]].value] | @csv)’
sparql.json > sparql.csv
結果をPalladioへエクスポートする
人気のデータ探査プラットホームPalladioは、直接SPARQLエンドポイントからデータを読み込むことができます。「新規プロジェクトの作成」の画面で、画面の下部にある「Load data from a SPARQL endpoint (beta)(SPARQLエンドポイントからデータを読み込む(ベータ版))」のリンクから、エンドポイントのウェブアドレスを入力するフィールドとクエリの入力欄が表示されます。エンドポイントによっては、エンドポイントアドレスでファイルの出力形式を指定することもできます。例えば、大英博物館のエンドポイントからデータを読み込むには、こちらのアドレスhttp://collection.britishmuseum.org/sparql.jsonを使う必要があります。試しに、さきほど芸術作品を種別ごとにカウントするのに使ったアグリゲーションクエリ内にペーストし、「クエリを実行」をクリックしてみてください。Palladioが検索結果のプレビューを表示するはすです。
エンドポイントから返されたデータのプレビューを確認したら、画面下の「Load data(データ読み込み)」ボタンをクリックして、操作を開始します。(Palladioに関するより詳しいチュートリアルは、Programming Historianのレッスンをご覧ください。)例えば、1580年から1600年の間に作成された印刷物の画像へのリンクを返すクエリを作り、画像データを日付でソートした一覧は次のようになります。
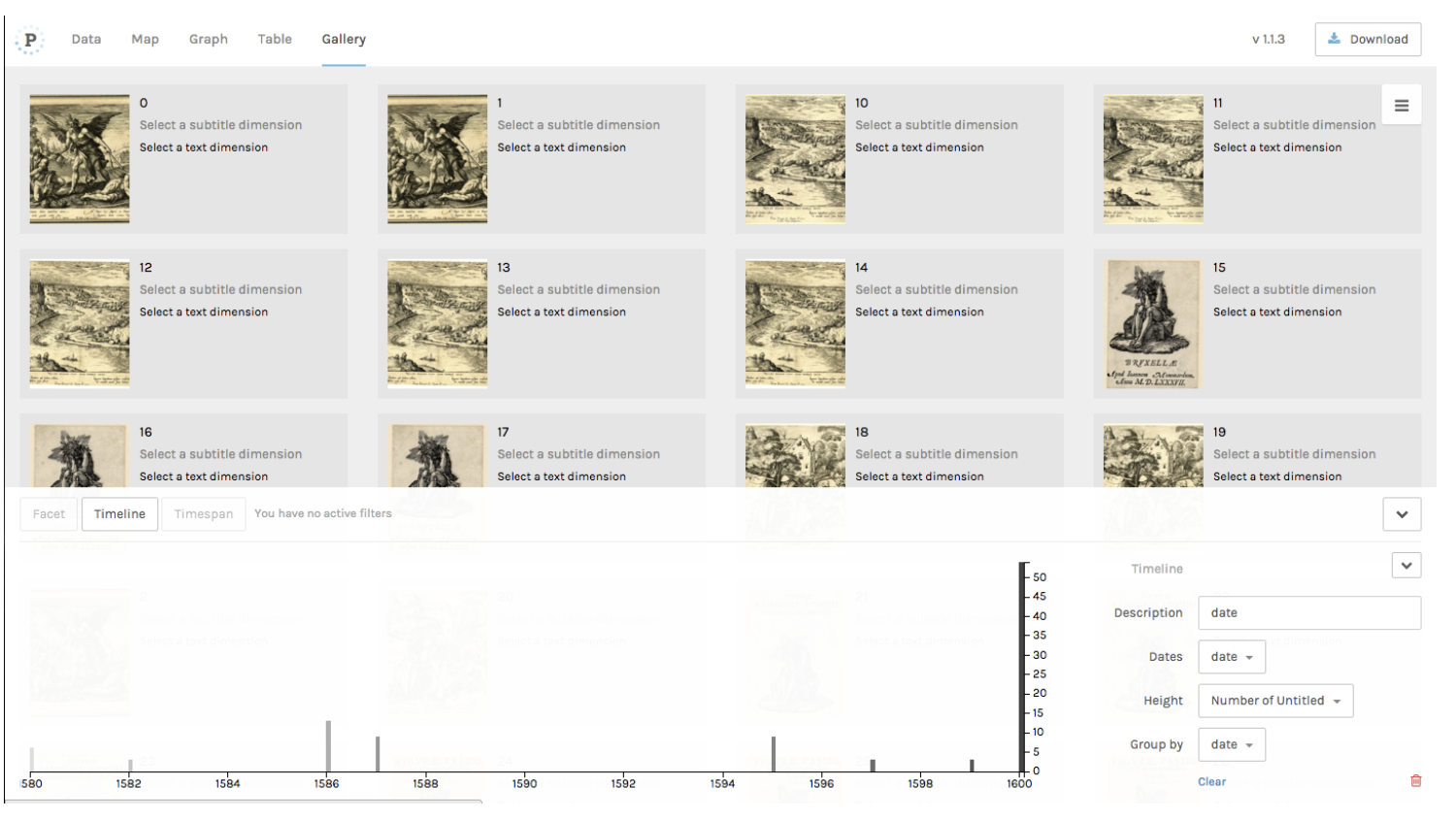
Palladioは、比較的少量のデータで作業するために設計されているため(数万単位ではなく数百から数千行程度)、Europeanaのエンドポイントへ問い合わせした際に受け取る結果の数を抑えるのに使ったLIMITコマンドを使って、ソフトウェアが固まらないようする必要があります。
参考文献
このチュートリアルでは、LODの構造について、大英博物館のデータベースに対するSPARQLクエリの書き方の事例を交えながら、考察しました。また、アグリゲーションコマンドをSPARQLで使うことで、単純に結果を一覧表示させるのでなく、グループ化やカウント、ソートの方法についても学びました。
例えば、ORやUNIONステートメント(条件分岐のクエリを記述することが可能)、CONSTRUCTステートメント(定義済のルールに基づいて新しいリンクを推測)、フルテキスト検索、数え上げよりもより複雑な数学的操作を行うといった手法を導入して、クエリをよりよく整えていく方法はもっとたくさんあります。SPARQLで利用できるコマンドのより詳しい概要については、これらのリンクをご覧ください。
EuropeanaとGetty Vocabulariesの両方のLODサイトでは、データを検索する方法を理解するための優れた情報源となり得る、非常に複雑で広範なクエリの事例を紹介しています。
著者について
Matthew Lincolnは、カーネギーメロン大学のデジタル・ヒューマニティーズのデベロッパであり、また、近世ヨーロッパの美術史家でもあります。
<ORCIDID>
引用の際はこちらをご利用ください
<原著>
Matthew Lincoln, “Using SPARQL to access
Linked Open Data,” The
Programming Historian 4 (2015), https://programminghistorian.org/en/lessons/retired/graph-databases-and-SPARQL.
<翻訳記事>
Matthew Lincoln著. 菊池信彦訳. SPARQLを使ってリンクト・オープン・データ(LOD)へアクセスする. 東アジアDHポータル. 2020. https://dhportal.ac.jp/?p=377.

この 作品 は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。