Go Sugimoto
このレッスンでは、アプリケーションプログラミングインタフェース(API)を介して他のウェブサイトから取得したデータをウェブサイトに入力する方法を紹介します。いくつかの簡単なプログラミングを使用して、そのデータの表示をカスタマイズするための戦略を提供し、柔軟で汎用的なスキルを提供します。
目次
ねらい
オープンデータへのアクセスや配布の手段として、API(Application Programming Interfaces)が頻繁に利用されています。実際、ここ数年、多くの人文科学研究者がAPIを使ってウェブ上でデータを共有し始めています。その結果、数多くの貴重なデータセットが利用できるようになりました。しかし、APIは開発者向けに作られていることが多く、技術的な経験の少ない研究者がAPIを利用するのは容易ではありません。
このチュートリアルでは、読者はプログラミングの予備知識なしに、APIの基本を素早く学び、ウェブ上で利用可能な膨大なデータ(多くの場合、自由に利用可能)にアクセスできるようになります。特に、基本的なHTMLとPHPを学ぶことで、Europeana APIを使用して、文化遺産コレクションのAPIクエリ結果を表示する簡単なウェブサイトを構築することができるようになります。この技術は汎用的なものなので、ハーバード美術館のAPIを使ってテストするための短いテンプレートも作成します。このチュートリアルでは、APIを幅広い文脈で理解するために、メタデータやウェブサーバといった他の概念についても説明します。
PHPは特にWeb開発に適したプログラミング言語であり、HTMLはWebページやアプリケーションを作成するためのマークアップ言語です。このレッスンの例では、いくつかの基本的なプログラミングを使用しますが、基礎レベルでAPIを使用する場合はコピー&ペーストで使用することも可能です。
内容
このチュートリアルは2つのパートで構成されています。最初のパートはAPIの基本的な理論を提供します。
- APIとは何か?およびウェブの簡単な歴史
- なぜAPIが役に立つのか?
第二部では、実践的な例が始まります:
- Europeana APIキーの登録
- ウェブブラウザでEuropeana APIデータを確認する
- XAMPPのインストール
- ローカルWebサーバーを利用し、PHPとHTMLでWebページを作成する
- PHPとHTMLを使ったEuropeana APIのウェブページ開発
- ハーバード美術館APIにアクセスするためのAPIテンプレートの作成
ソフトウェア要件
- ウェブブラウザ(Firefox、Internet Explorer、Chrome、Safariなど)
- テキストエディタ(Atomを推奨)[訳注:Atomは2022年末をもってすでに開発が終了しています。代替テキストエディタとして、例えばVisual Studio Codeなどがあります。なお、以下本記事には、Atomに関する記述がありますが、すべて他のテキストエディタに読み替えてください。]
- XAMPP
XAMPPはフリーのPHP開発プラットフォームです。XAMPPには、このチュートリアルに必要な2つの重要なパッケージが含まれています。それがApache WebサーバーとPHPです。これらを使い、ウェブサーバ上にテストウェブサイトを作成し、PC上でAPIへのアクセスをシミュレートすることができます。
Application Programming Interface (API)とは何か?
インターネットのこれまでの物語
このチュートリアルでは、ウェブAPI(ウェブ上で使用されるAPI)についてお話します。というのも、人文学研究で非常にしばしば使わているからです。ウェブAPIを説明するために、ワールド・ワイド・ウェブ(WWW)が(ティム・バーナーズ=リー卿によって)誕生した1989年に戻ってみましょう。WWWは当初、人間と機械(コンピュータ)のコミュニケーションのために設計されました。私たち人間がコンピュータ上でウェブサイトを作成し、他の人間がウェブブラウザを使うことでコンピュータのそれを見るというものでした。当時はほとんどが静的なウェブページでした。それというのも、当時のウェブページは文書であり、ウェブ管理者によってコンテンツが固定されていたためです。GUI(グラフィカル・ユーザー・インターフェイス)でテキスト(ハイパーリンクで相互に接続されたもの)や写真が表示される、他の誰かのウェブページを受身的に見るだけでよかったのです。双方向的なやりとりのほとんどは人と機械との間で行われたのであり、機械が人間のコミュニケーションを「調整」していたと言えるでしょう。
その後、私たちはダイナミックなウェブページを作成するようになり、そこでは人間のユーザー同士が相互にやりとりできるようになりました。ウェブページは動的なもので、コンテンツは固定されたものではなく、ユーザーのアクションによって動的に変化するものでした。ソーシャルメディアはその典型的な例です。私たちはウェブコンテンツを消費するだけでなく、生成することもあります。このようなウェブリソースを管理するために、私たちはウェブサイトの背後にデータベースシステムを必要としました。ユーザーの生み出すコンテンツが普及したことで、大規模なデータベースが構築され、さらに、何百万、何十億というウェブサイトやデータセットの膨大な量のデータが生成されるようになりました。
ここにきて私たちはもっと機械同士のコミュニケーションが必要だと気づきました。人間が実際に閲覧したり作業したりできる量をはるかに超えるデータがあるため、機械同士がスムーズに通信できる方法が必要でした。この方法はウェブサービスと呼ばれています。APIは代表的なウェブサービスです。APIにはさまざまな種類があります。機械がデータをリクエストして取得するだけでなく、送信されたデータを処理することもできます。このチュートリアルでは、研究目的で有用なデータを取得することに焦点を当てます。
実際の状況を考えてみましょう。あなたはスキー場のウェブサイトを管理しており、30分ごとにスキー場の天気予報を更新したいと考えています。あなたは気象データを含む気象ウェブサイトから予報を受け取ります。そのようなウェブサイトを自分でチェックし、手動でデータを更新するよりも、自動的に気象データを取得し、一定の間隔で表示できるウェブサイトを構築する方が簡単です。つまり、ウェブサイトが別のウェブサイトと通信するのです。このような機械と機械のデータ交換や自動化は、APIを使うことで可能になります。気象サイトのAPIは、一種の(データベース)サービスとみなすことができます。
APIを使ってウェブサイトを作成することと、ウェブサイトのスニペットをウェブサイトに埋め込むことには違いがあります。APIは通常、標準化された生データとアクセス方法を提供します。つまり、データを扱ってカスタマイズするのが簡単になるのです。例えば、APIを使えば、華氏を摂氏に変換したり、棒グラフの代わりに折れ線グラフを表示したりすることができます。さらに、APIを利用することで、ウェブ開発者はデータとデザインを切り離すことができます。これによって、フレキシブルなウェブサイトを構築するのがとても楽になります。
ウェブサイトはウェブページとAPIの両方を提供できることを知っておくことは重要です。例えば、人間のユーザーがウィキペディアのウェブサイトを訪れ、あらかじめデザインされた記事を読む一方で、ウィキペディアは他のユーザーにAPIを提供し、ウィキペディアの機械可読性のある生データを使ったアプリを開発できるようにもしています。APIの作成は任意であるため、APIを持たないウェブサイトもたくさんあります。しかし、APIの数はかなり増えています。
なぜAPIは研究者にとって有用なのか?
上記のAPIの技術的な利点とは別に、普通の研究者にとっての利点はどのようなものでしょうか?例えば、以下のようなものを利用したいと思うかもしれません。
- より多くのデータ
- 関連するデータ
- 相互にリンクしたデータ
- 遠くにあるデータ
- 最新のデータ
- さまざまな種類のデータ(学際的研究)
- より質の高いデータ
- (自分では)取得できないデータ
- 低価格のデータ、または無償のデータ
一般的に、研究者はデータを共有し再利用することで、インターネットの力というものを活用したいと考えています。そのため、「オープンデータ」や「データ駆動型研究」が、ここ数年、学界や産業界で脚光を浴びているのです。APIは、この動きの中で成長している分野の一つです。幅広い大規模データセットにアクセスすることで、私たちは以前よりもはるかに多くのことができるようになり、研究実践に大きな変化をもたらし、より多くの新しい発見やイノベーションが生まれることが期待されています。
以下のセクションから、実際のシナリオのもとで、APIを使った旅へと出かけましょう。
Europeana API
最初に試すAPIはEuropeanaです。これは、ヨーロッパの文化遺産に関する最大の情報源のひとつです。ヨーロッパ中の博物館、文書館、図書館からデータを集めています。この記事を書いている時点で、5,000万件以上のオブジェクトが含まれています。写真、絵画、書籍、新聞、手紙、彫刻、コイン、標本、3Dビジュアライゼーションなどがあります。
このセクションの目標は、Europeana APIデータをリクエストし、表示させるWebサイトを作成することです。ステップバイステップでタスクを完了するために、Europeana APIに登録する方法、ウェブブラウザでAPIデータにアクセスする方法、XAMPPをインストールする方法、簡単なウェブページを作成する方法、APIデータを表示するウェブページを開発する方法を学びます。
ここからEuropeana APIのドキュメントに目を通すこともできますが、このチュートリアルを完了した後に行うことをお勧めします。
APIの登録
Europeana APIを使用するには、キーの登録が必要です。登録は無料で、ウェブサイトから行うことができます。
- Europeana APIのウェブサイトで自分の個人情報を入力する
- リクエストキーボタンをクリックする
- Eメールの受信トレイにAPIキーが届く。APIキーは英数字で構成され、あなた固有のものです
APIを初めて使う
最初のAPIリクエストはできるだけ簡単に行う必要があります。APIキーとウェブブラウザがあればできます。技術的なことはひとまず忘れて、以下のURLをコピーしてウェブブラウザのアドレスバーに貼り付けてください。YOUR_API_KEYの部分は、メールで受け取ったご自身のAPIキーに置き換えてください。
https://www.europeana.eu/api/v2/search.json?wskey=YOUR_API_KEY&query=London何が表示されましたか?たくさんのテキストが見えるはずです。もしそうなら、おめでとうございます。これがあなたの最初のデータビューです。あなたはすでにEuropeana APIを使っているのです。もし「Invalid API key(無効なAPIキーです)」というエラーメッセージが表示された場合は、APIキーがURLに正しくコピーされていることを確認してください。
Firefox 66.0.5以降をお使いの場合、より整理された構造化データが表示される可能性があります。Internet Explorerやその他のブラウザをお使いの場合は、以下のようなメッセージが表示されることがあります。その場合は、ファイルを保存し、テキストエディタ(メモ帳やAtomなど)で開いてください。

上の例でブラウザのURLボックスに入力した内容を詳しく見てみましょう。これは単なるURLです。ウェブサイトを見るときとまったく同じです。例えば、Europeanaのウェブサイトを見るのに、https://www.europeana.euというURLを入力します。しかし、いくつかの違いがあります。wskey=の後にAPIキーを入力します。これは、あなたがこのウェブアドレスにアクセスするのに許可されたということを意味するものです。そのあと、query=Londonと続きます。その通り。私たちはEuropeanaのデータベースに対して、”London”という検索キーワードで問い合わせをしているのです。Europeanaはいくつか種類の異なるAPIを提供していますが、このチュートリアルでは検索APIを使用しています。

APIデータを(JSONで)理解する
お使いのブラウザがJSONの表示をサポートしていない場合(最新のFirefoxにはJSONビューワがプリインストールされているはずです)、データ全体をコピーしてオンラインのJSONビューワにペーストしてください。データの階層を展開したり(+ボタン)折りたたんだり(-ボタン)することで、より簡単にデータを見ることができます。
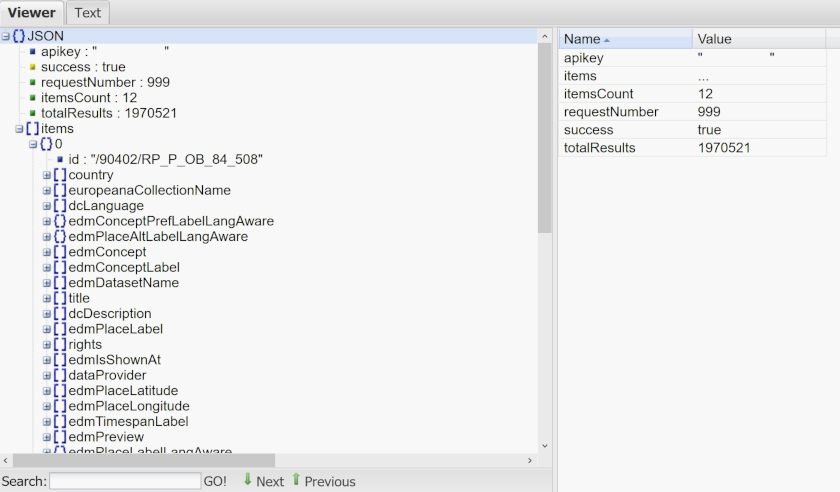
さて、データの最初の行を注意深く見ると、気づくことがあるでしょう。
{"apikey":"YOUR_API_KEY","success":true,"requestNumber":999,"itemsCount":12,"totalResults":1967341,文字通り、”apikey”はあなたのAPIキーです。APIアクセスがsuccess(成功)しています。requestNumberは無視できますが、1967431件のtotalResultsのうち、最初の12アイテム(レコード)だけが返されています(これはデータの氾濫を避けるためです)。それ以降は、コレクションから返された実際のデータ (つまり12アイテム)が表示されています。
データを整理するために、EuropeanaはJSON(JavaScript Object Notation)と呼ばれる特定のフォーマット/構造を使用しています。データは中括弧でくくられます(これはオブジェクトと呼ばれます)。これは常に { で始まり、 } で終わります。その内部では、データは文字列のペアで表されます。それぞれのペアは、コロン(:)で区切られた2つの要素を持ちます。例えば、“totalResults”:1967341のようになります。この形式を名前と値のペアと呼びます。この場合、名前は“totalResults”で、1967341がデータ値となります。複数のペアがある場合、名前と値のペアはコンマ( , )で区切られます。まとめると、最も単純なJSONデータは次のようになります:
{
"name 1": "value 1",
"name 2": "value 2"
}名前を指定することで、それに対応するデータ値を取得するクエリを作成することができます。このように、JSONは非常にシンプルなデータ形式なので、人間にとって理解しやすいだけでなく、機械(コンピュータ)にとっても処理しやすいデータ形式です。このため、皆がこのデータ形式に従っている限り、機械と機械との間の通信が容易になります。この理由から多くのAPIでJSONは利用されています。名前-値(「キー-値」とも呼ばれる)ペアは、データを入れておくためにプログラミングでよく使われるので、この構造を知っておくとよいでしょう。
Europeanaの検索APIでは、ユーザーの関心のある実際のデータはitemsのなかに保存されます。ここでは、少し異なる構造を参照してください。これは、数字([0], [1], [2]…)と角括弧で数字を含んでいます。それぞれの括弧はアイテム/レコードで、12個のレコードがあります。角括弧は配列と呼ばれる値の順序付きリストを表します。最初の項目は0です。初めは少し奇妙に感じますが、これは規則なので、そのまま理解してください。配列はJSONのデータ型の1つです(PHPのデータ型については後述します)。名前と値のペアと同様に、ただ数値を指定することで、リストのなかのデータを取り出すことができます。各配列の中には、名前と値のペアがあります。配列が繰り返されるように、名前が入れ子構造になっていることもあります。Europeana APIでは、この部分は各レコードに依存します。レコードによっては他のレコードよりもデータが多い場合があり、そのためデータ構造や値に一貫性がないケースがあります。
レコードには名前の長いリストがあるので、いくつかその名前を説明しましょう:
| 名前 | 説明 | 値の例 |
| iD | このアイテムの識別子 | /9200309/BibliographicResource_3000093757119_source |
| country | データ提供者の国 | Belgium |
| dataProvider | このアイテムのデータ提供者 | Royal Library of Belgium |
| rights | あらかじめ定義された権利に関する声明(クリエイティブ・コモンズなど) | http://rightsstatements.org/vocab/InC/1.0/ |
| title | このアイテムのタイトル | Stand Not Upon The Order Of Your Going, But Go At Once Shakespeare Macbeth 3-4 Enlist Now |
| edmPreview | このアイテムのEuropeanaでのプレビューのURL | https://www.europeana.eu/api/v2/thumbnail-by-url.json?uri=http%3A%2F%2Fuurl.kbr.be%2F1017835%2Fthumbs%2Fs&size=LARGE&type=IMAGE |
| edmIsShownAt | データ提供者のウェブサイトにおけるアイテムのURL(ウェブページ | http://uurl.kbr.be/1017835 |
| edmIsShownBy | データ提供者のウェブサイトにおけるこの項目のURL(メディアファイル | https://www.rijksmuseum.nl/nl/collectie/RP-P-OB-84.508 |
| type | アイテムの種類 | IMAGE |
| guid | EuropeanaのアイテムページのURL | http://www.europeana.eu/portal/record/90402/RP_P_OB_84_508.html |
Europeanaのデータモデル(Europeana Data Model: EDM)について説明することは、このチュートリアルの範囲外ですが、すべてのレコードはEuropeanaのデータモデルに基づいているため、簡単な説明があると便利です。EDMは文化遺産に関するさまざまな記述(メタデータ)で構成されています:
- 文化遺産(博物館、図書館、文書館に収蔵されているもの)を記述するためのダブリンコアメタデータ。タイトル(Mona Lisa)、作者(Leonardo da Vinci)、大きさ(77 cm × 53 cm)、年代(1503-1517?)、場所(France)、所有者(Louvre museum)、種類(painting)など、主に物体の物理的な側面についての記述が含まれている。Europeana APIでは、接頭辞 dc で指定されることが多いです。
- 物理的な資料のデジタル化データに関するメタデータ。ユーザーがその資料を閲覧できるURL(Europeanaウェブサイトと外部ウェブサイトの両方)、デジタルフォーマット(jpg)、ライセンス情報(クリエイティブ・コモンズ)などが含まれます。
EDMの詳細については、ドキュメントを参照してください。
上の例ですでにお分かりのように、API経由でデータを見るには、ウェブブラウザがあればよいのです。また、Europeanaの場合は Europeana Rest API Consoleを使用することもできます。ここでは、パラメータ(例えば、検索キーワードとして”London”)を設定すれば、追加のソフトウェアをインストールすることなくデータを確認することができます。
Europeanaのデータセットを検索・閲覧するのは良いのですが、生データやデフォルトのデータ表示しか表示できないので、あまり便利とは言えません。そこで、ウェブブラウザから離れて、データ表示をカスタマイズしてみましょう。
次のステップでは、ウェブページを開発します。この開発作業を行う際には、APIデータビューをウェブブラウザで開いておくとよいでしょう。というのも、この方法でデータを調べることが多いからです。
XAMPPのインストール
ここで、新しい開発環境をセットアップする必要があります。XAMPPのウェブサイトにアクセスし、お使いのOSに合ったソフトウェアをダウンロードし、インストールしてください。現在のバージョンは7.2.9です[訳注:翻訳時は8.2.4]。以下の手順に従っていただければ、インストールはとても簡単ですが、XAMPPを実行する必要があるので、どの場所にインストールしたかは覚えておいてください。
Windows
- ダウンロードしたファイル(exe)をダブルクリックしてインストールを開始します
- デフォルトでは、XAMPPは以下の場所にインストールされているはずです:C:\xampp
- 詳しいチュートリアルはこちら
Mac OS X
- ダウンロードしたファイル(dmg)をダブルクリックしてインストールを開始します。
- デフォルトでは、XAMPPは以下の場所にインストールされているはずです: /Applications/XAMPP
- 詳しいチュートリアルはこちら
LINUX
- パーミッションの変更 (chmod 755 xampp-linux-*-installer.run)
- インストーラを実行します (sudo ./xampp-linux-*-installer.run)
- デフォルトでは、XAMPPは以下の場所にインストールする必要があります:/opt/lamp フォルダ
- 詳しいチュートリアルはこちら
XAMPPとPHPでの初めての試み
インストールが完了したら、Europeanaのデータにアクセスできるウェブサイトの構築を始めましょう。まず、XAMPPを開きます。Windowsの場合、スタートメニューからXAMPP Control Panelをクリックします。MACの場合はXAMPP Controlを開きます。XAMPP Controlの名前は”manager-osx”です。
もし[Module列の]”Apache”の部分が緑色で表示されていない場合は、[ActionsのStart]ボタンをクリックしてApacheを起動してください。そうすれば、ローカルマシンで使用することができます。
Linuxユーザーの方へ
- 以下のコマンドでXAMPP Control Panelを起動します。
cd /opt/lampp
sudo ./manager-linux.run (or manager-linux-x64.run)Skypeを使用している場合、Skypeが同じポート(80と443)を使用している可能性があるため、XAMPPが動作しない可能性があります。その場合は、アプリケーションを終了するか、ポートを変更してください(解決策を参照)。
上記のような画面が表示されれば、すべてOKです。[XAMPPを]インストールしたフォルダに行くと、htdocsというフォルダがあるはずです(Mac OSXの場合、/Applications/XAMPP/xamppfiles/htdocs)。デスクトップにショートカットを作成することをお勧めします。このフォルダにウェブサイト作成に必要なファイルをすべて置く必要があるので、便利な場所にあるのがベストです。現在、このフォルダにはXAMPPが用意したデフォルトのファイルしかありませんので、全く新しいPHPファイルを作成しましょう。htdocsフォルダの中に、テキストエディタで新しいテキストファイルを作成し、helloworld.phpと名前を付けて保存します。
ご存知かもしれませんが、新しいプログラミング言語を初めて学ぶときに”Hello World”と表示させるのは開発者の伝統です。テキストエディタでhelloworld.phpを開き、次のように入力(またはコピー&ペースト)して保存してください。
<?php
print 'Hello World';
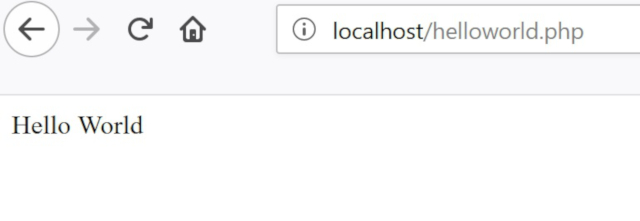
?>ウェブブラウザを開き、アドレスバーに http://localhost/helloworld.php と入力します。PHP コードを編集する際には、編集中のウェブページをブラウザで開いておくことをお勧めします。ファイルを保存すれば、すぐにその結果を確認できますので。
ブラウザのウィンドウに白い背景に”Hello World “と表示されるはずです。おめでとうございます。これで最初のPHPプログラムが完成しました。PHPのコードは常に <?phpで始まり、?>で終わります。JSONのように、これらの行がファイルがPHPであることを宣言しているのです。 printは、次のコード’Hello World’をテキストとして表示することを意味します。PHP では、データ型が文字列 (テキスト) であることを示すために ‘ ‘ または ” ” (シングルクォートまたはダブルクォート)を使用することができます (整数、ブール値、配列など他のデータ型もありますが、ここでは文字列にフォーカスします)。
HTMLでの初めての試み
この例では、PHPは‘Hello World’を通常のテキストとして使用しています。しかし、PHPはHTMLもうまく扱うことができます。HTMLはWebページやアプリケーションを作成するマークアップ言語です。(WebブラウザでWebサイトのHTMLを見るには、ホームページのテキストエリアで右クリック(またはブラウザの上部メニューバー)し、”ページのソースを表示”を選択します)。
では、PHPを使ってHTMLを書くために少し変更を加えてみましょう。
'Hello World'を
'<b>Hello World</b>'に変えてみてください。
ファイルを改めて保存し、次にブラウザで同じページを更新します。ウェブサイトを開発する際には、ウェブページを頻繁にリロード/再読込することに慣れておくとよいでしょう。HTMLを使った変更結果は、ページが更新されるまで表示されないかもしれません。
“Hello World”が太字になったはずです。これは、HTMLタグの<b></b>がタググで囲まれたテキストを太字にするものだからです。HTMLは基本的に、間にあるコンテンツに注釈を加えます(<b>は太字を意味します)。
ほとんどのHTMLタグには、開始タグ(<b>)と終了タグ(</b>)が必要なので注意してください。これらを間違えたり省略したりすると、ウェブブラウザが情報を正しく表示できないことがあります。
プログラミング全般において、忍耐と正確さが必要かもしれません。入力ミスや入力漏れがあると、コンピューターはあなたの要求や意図を理解できないかもしれません。ですから、自分のコードをよくよく確認してください。
HTML、画像とリンク
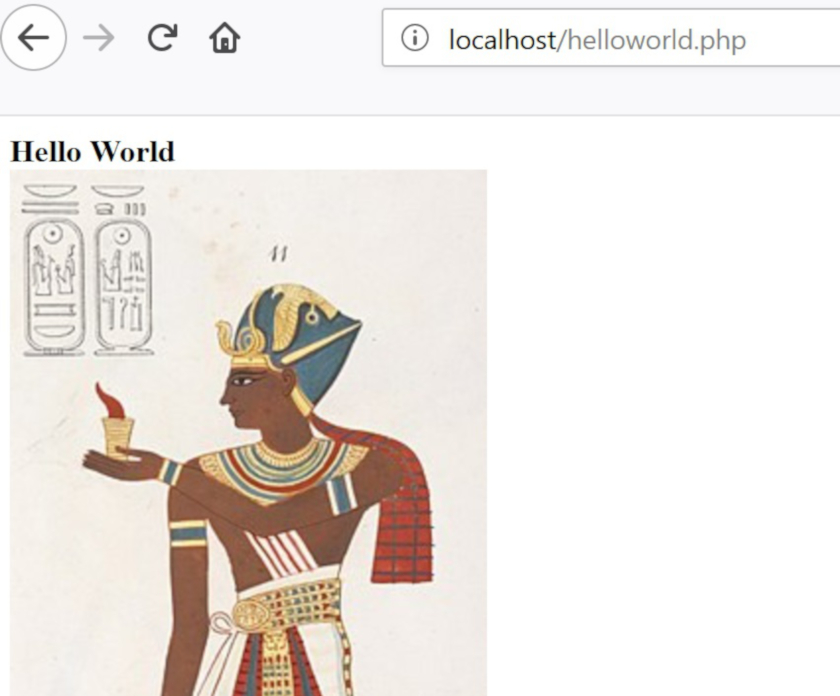
APIに進む前に、基本的なHTMLとPHPコーディングで簡単なウェブサイトを作成する練習をしたいと思います。まず最初に、PHPのWebページに画像を表示します。前の例を次のように変更して保存します。最初の行が少し変わり、最後に改行を意味する<br>が追加されていることに注意してください。
<?php
print '<b>Hello World</b><br>';
print '<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/7/79/Ramesses_Vi_closeup.jpg/242px-Ramesses_Vi_closeup.jpg">';
?>上記のファイルをウェブブラウザで表示すると、太字で”Hello World”と表示され、次の行に画像が表示されるはずです。新しい3行目は、画像を挿入するためのHTMLコードを表示しています。
<img src="URL TO IMAGE">これは、HTMLタグ全体をシングルクォートで囲むことで行います。
HTMLでは、(囲んでいる)タグを要素と呼びます。要素内には属性があり、これは要素を設定したり動きを調整したりする付加的な値です。通常、属性は名前と値のペアとして表示され、 = で区切られます。例えば、<img>は要素で、src=””は属性です。
htdocフォルダに画像を置く場合、http:// の代わりにIMAGE FILE (例:”MyImage.jpg”)というフォーマットで指定することもできます。
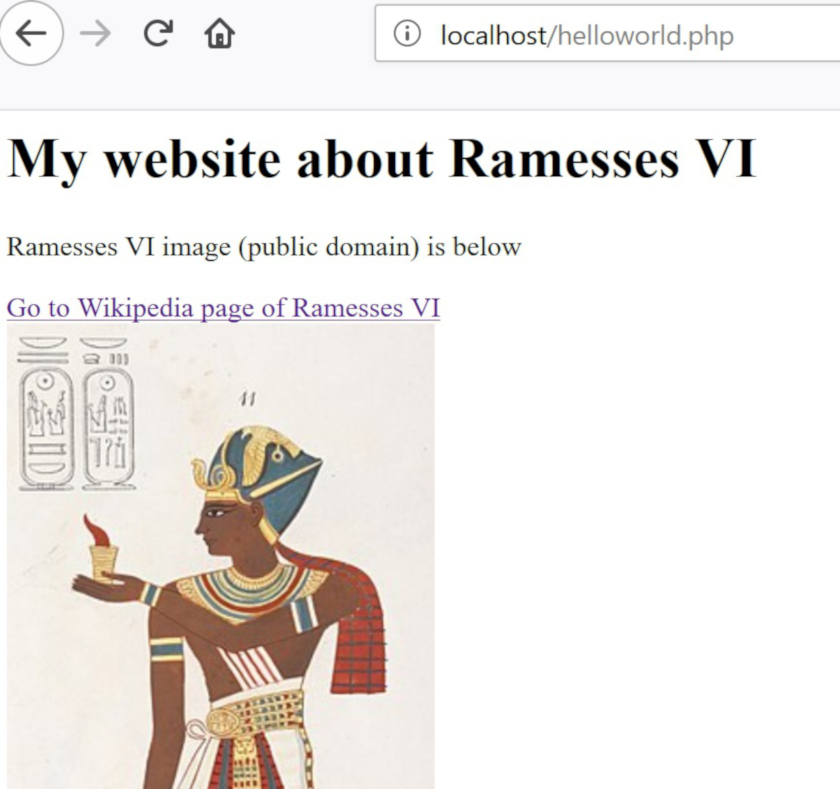
では、本物のウェブサイトを作ってみましょう。インターネットの本当の力はハイパーリンクにあるので、ウィキペディアへのリンクを追加します。次のコードをコピー&ペーストして、前の例全体と置き換えてください。
<?php
print '<h1>My website about Ramesses VI </h1>';
print '<p>Ramesses VI image (public domain) is below</p>';
print '<a href="https://en.wikipedia.org/wiki/Ramesses_VI">Go to Wikipedia page of Ramesses VI</a><br>';
print '<img src="https://upload.wikimedia.org/wikipedia/commons/thumb/7/79/Ramesses_Vi_closeup.jpg/242px-Ramesses_Vi_closeup.jpg">';
?>本当のウェブサイトのようではないですか?<h1>はHTMLの見出しタグ(最も大きなサイズ)で、<p>はHTMLの段落(つまり通常のテキスト)です。 <a>はハイパーリンクタグで、href=でURL(この場合はウィキペディアの記事)を指定します。属性には、実際のコンテンツに表示させたくない要素に関する別の情報が含まれていることが多いため、長いURL(https://en.wikipedia.org/wiki/Ramesses_VI)の代わりに“Go to Wikipedia page of Ramesses VI”(ラムセス6世のウィキペディアページへ)というテキストを表示させています 。
あなたがたった今作成したものは、インターネット上のすべてのウェブサイトの本質であり、テキスト、ハイパーリンク、メディア(画像)を含んでいます。唯一の違いは、ほとんどのウェブサイトは、より良いレイアウト、より多くの装飾、そしておそらくインタラクティブな機能を持っているということです。よくできました。あなたはウェブマスターになったのです。
Europeana APIをPHPで扱う
ここからようやく、PHPについて学んだことを利用してAPIに取り組みたいと思います。プログラミングの詳細には触れませんが、一つ重要なことを知っておいてください。
プログラミングでは変数をたくさん使います。これらは基本的に参照です。ある意味、JSONでの名前と値のペアにおける名前に似ています。値が格納される場所に名前を付けることで、予測不可能な値や変更可能な値に、あらかじめ決められた名前からアクセスできるようにするものです。値を使用する必要がある場合は、その値を含む変数を参照すればよいのです。
PHPでは、変数は接頭辞 $ で表します。作家がよく “floccinaucinihilipilification “と言うと仮定しましょう。”floccinaucinihilipilification”とは最も長い英単語の一つで、どうでもいいことをする行為を意味します。例えば
$it = 'floccinaucinihilipilification';
print '<p>I think he is doing '.$it.' again</p>';構文の細かいところは気にしないでください。ここでは核となる概念を理解できれば十分です。まず、この長い単語を”it”( $it )という変数に入れます。そして、 $it を使って2行目の長い単語を参照できるようにします。その結果、”I think he is doing floccinaucinihilipilification again “というHTML段落が出来上がります。まるで数式のようです。下の例は説明なしで理解できるでしょう。xとyは数値を含んだ変数なのです。
x = 10
y = 5
x + y = 15また、変数に数値を代入することで、数式の計算が簡単になります。例えば、ある国の2018年の人口を変数に入れ、コード内のさまざまな統計計算に使用したとします。その後2019年の人口に情報をアップデートする必要が出てきました。ですが、あなたがしなければならないことは、ただ変数の値を変更することだけです。その変数に基づくすべての計算は自動的に更新されます。ですから、コードは非常に柔軟で再利用可能です。
それではeuropeana_api.phpという名前で新しいPHPファイルを作成しましょう。そのPHPファイルに、以下のコードをコピー&ペーストしてください。(YOUR_API_KEYを置き換えますが、YOUR_API_KEYの前後の ‘ は削除しないでください。変数が文字列であること(PHP のデータ型を覚えていますか?)とそれを残しておくことが重要です。)ブラウザを localhost/europeana_api.phpのURL に移動します。
<?php
$apikey = 'YOUR_API_KEY';
$contents_europeana = fopen("http://www.europeana.eu/api/v2/search.json?wskey=$apikey&query=London&reusability=open&media=true", "r");
$json_europeana = stream_get_contents($contents_europeana);
fclose($contents_europeana);
print $json_europeana;
?>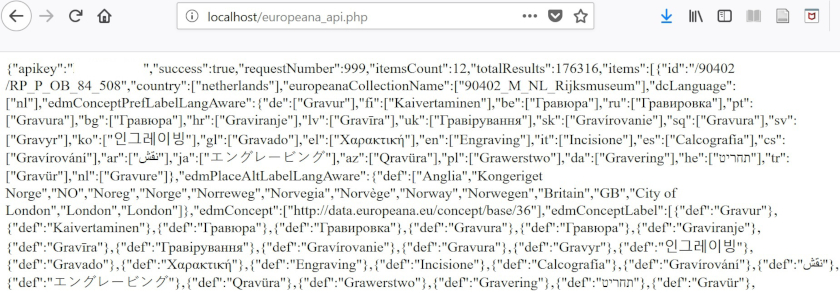
見慣れたデータでしょう?先ほどウェブブラウザで見たのと同じJSONデータです。しかし、大きな違いは、Europeanaのサーバーではなく、私たちのウェブサーバー(localhost)で見ているということです。
このコードがどのように動作するか、一行ずつ考えてみましょう。最初の行では変数 $apikey を定義し、YOUR_API_KEYの値を格納しています。こうすることで、毎回YOUR_API_KEYを入力する必要がなくなります。今回はあまり使いませんでしたが、将来何が起こるかわからないので、良い練習になります。次の行では、別の変数 $contents_europeanaを定義しています。これは、Europeana API からのデータを格納するために使用します。
fopen()は、“http://www.europeana.eu/api/v2/search.json?wskey=”.$apikey.”&query=London&reusability=open&media=true” からデータを開いてください、という意味です。また、ファイルへの書き込みは行わず、コンテンツの読み込み(“r”)のみを行っています。URLには$apikeyが含まれているので、これは、”http://www.europeana.eu/api/v2/search.json?wskey=YOUR_API_KEY&query=London&reusability=open&media=true “と同じです。
次の行では、別の変数 $json_europeanaを宣言し、その値として stream_get_contents($contents_europeana)を割り当てています。$json_europeanaが先ほど開いたデータを取得しています。データを開いたのと同じように、fcloseで閉じています。ここで、$contents_europeanaという変数が同じことを繰り返さないという良い役割を果たしています。ここまでは、すべてが舞台裏で行われていて、ブラウザには何も表示されません。print $json_europeana;だけで、変数$json_europeanaの値、つまりあなたがすでに知っているJSONデータを表示することができているのです。
JSONデータを操作するには、PHPフォーマットでこれを使用する必要があります。europeana_api.phpの最後の部分、PHPを( ?> )で閉じる前に次の3行を追加して、保存してみてください。
$data_europeana = json_decode($json_europeana);
print '<hr>';
print $data_europeana->totalResults;ブラウザを更新すると、ブラウザには同じJSONデータが表示されますが、一番下を見ると横線と数字が追加されています。

json_decodeは$json_europeanaの値(JSON形式)をPHPコードに変換します。HTMLのhrタグは、JSONデータの上下を区別するために横線を引くものです。これは絶対に必要というわけではありませんが、読みやすくするために使っています。$data_europeana->totalResults;はtotalResultデータを表示するものです。->を使うと、階層データの特定の位置を参照してデータの値(この場合はtotalResults)を取得することができます。このように、表示させたいデータの一部を指定することができているのです。
次のステップは、このチュートリアルにおけるEuropeana検索APIへの最終的なアプローチです。これまでと同じデータを使って表形式の表示を作成し、データの表示方法をカスタマイズする経験を積んでいきます。
Europeanaデータのテーブルビューの作成
これまでのところ、アクセスしたデータは読みやすいものではありませんでした。そこで、データを再編成して、テーブル[表]ビューを作成してみましょう。すでに行った作業にコードを追加していきます。print $json_europeana;とprint $data_europeana->totalResults;を削除し、europeana_api.phpの最後に以下のコードを追加してください。改めて言いますが、PHPのコードを閉じる( ?> )の前にお願いします。ファイルをブラウザで見てください。ヘッダー行のあるテーブルが見えるはずです。後でその表にデータを入れるだけです。
print '<hr>';
// Table view of Europeana data
print '<table border=1><tr><th>Title</th><th>Data Provider</th><th>External Link</th><th>Thumbnail</th></tr>';
print '</table>';
上記のコードでは、hrタグは、以前の出力と現在作業中の表を視覚的に分離するために入れています。
2行目の // は「コメント」を意味します。これはコンピュータにこの行を無視するように指示するもので、”Table view of Europeana data “の部分はスキップされます。開発者は自分のコードに記録を残すためにコメントを使用し、将来そのコードが何のためにあるのか、何をするものなのかを理解できるようにしています。そのため、コードの履歴を記録しておくことがベストプラクティスなのです。
3行目では、HTMLコードで表を設定しています。詳しい説明はHTMLのチュートリアルにありますが、1行目の<table border=1> は1本の幅のボーダーラインを持つ表を定義しています。この例の最後にある print “</table>”; はHTMLの閉じタグです。<tr></tr>(テーブル行)が表のヘッダー行を生成するのに対して、<th></th>(テーブルヘッダー)は表のなかの列と見出し名を提供します。
次に、変数$data_europeanaに格納されているEuropeanaデータを操作します。tableタグと/tableタグの間のスペースに、以下のコードを追加します:
foreach($data_europeana->items as $item) {
print '<td><a href="'.$item->guid.'">' .$item->title[0].'</a></td>';
print '<td>'.$item->dataProvider[0].'</td>';
print '<td><a href="'.$item->edmIsShownAt[0].'">View at the provider website</a></td>';
print '<td><a href="'.$item->guid.'"><img src="'.$item->edmPreview[0].'"></a></td></tr>';
}ファイルを再度保存し、ブラウザを更新してください。現在表示されているのは、JSONのテキストデータが実際に含んでいるものです。画像を指すURLを持っているので、画像を表に表示することができます。
表にタイトル、データ提供者、外部リンク、サムネイルが入るようになりました。表の上側にエラーが表示されても心配しないでください(後で修正します)。ただ、作成したウェブページを探索し、何ができるかを感じ取ってください。
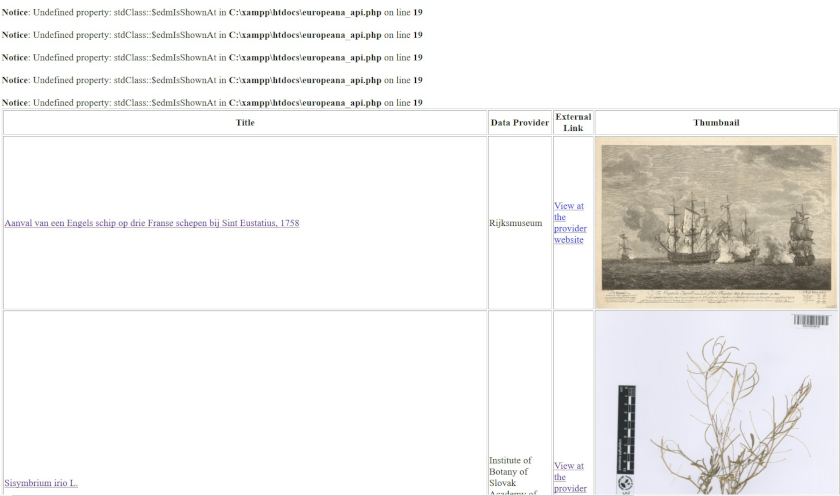
たったいま作ったものの背後にあるロジックを理解してみましょう。前述したように、Europeanaのレコードはitemsと呼ばれる配列に格納されています。この配列の中では、各データは順番に格納され、配列内の [0] から [11] までの場所に対応する番号でアクセスできます。配列内のデータを操作するには、foreach(){}を使用する必要があります。これは “Foreachループ “と呼ばれるもので、配列内の項目に対して処理を繰り返す関数です。今回の例では、丸括弧の中で配列の各レコードに $item という新しい変数を代入しています ($data_europeana->items as $item)。つまり、$itemという変数で、[0] から [11] までの各レコードにアクセスできるようにしているのです。ループは中括弧 {} で指定します。次の行を見るとわかりやすいので、ここでは飛ばします。データセットをプリントしなければならないので、表の中で何度もprintが使われています。<td></td>は表のなかの行を表します。
さて、EuropeanaのJSONデータを精査したいと思います。すべてのデータを表示させる必要がないので、表示させるべきデータを指定する必要があるからです。新しくウィンドウあるいはタブを開いて、次のURLにアクセスして下さい。http://www.europeana.eu/api/v2/search.json?wskey=YOUR_API_KEY&query=London&reusability=open&media=true
YOUR_API_KEYを適切な文字列に置き換えることを忘れないでください。JSONビューワを使って、取得したいデータを特定していきます。
foreachループの中を1行ずつ見てみましょう。printの各行は表のなかの列に対応しています。foreachループの中の最初の行は、表の最初のカラム”Title”となります。この行には<a></a>があり、リンクであることを意味しています。hrefは、ユーザーがリンクをクリックしたときにジャンプするターゲットURLを指定し、<a></a>の間はクリック可能なテキストになります。今は構文の詳細を無視してかまいませんが、今回の場合は $item->guid がURL で $item->title[0] がテキストです。
guidがEuropeanaのアイテムページのURLであるのに対し、titleはアイテムのタイトルです。titleの後に[0]を使っているのは、配列の最初の名前/キーにtitleが格納されているからです(配列には名前/キーが1つしかないこともあります)。その結果、リンクとテキストは最初のカラムで意図したとおりに動作します。
2つ目のカラムには、<td></td>以上のものはなく、テキストデータのみが挿入されることを意味しています。その中身はdataProvider[0]で、これは前のセクションで既に”Data Provider “というヘッダーを作成しているので理解できます。3つ目のカラムもlink要素です。リンクにはedmIsShownAt[0]が指定され、“View at the provider website”という簡単な文章が表示されます。最後のカラムにもguidのリンクがありますが、さらにその間に画像が作成されています。画像をリンクで挟むと、画像がリンクされクリック可能になります。したがって、edmPreview[0]で指定された画像をクリックすると、guidで指定されたウェブページへのリンクが張られます。動作しているかどうかはブラウザで再確認してください。
まとめると、foreachは配列に対してタスクをループさせます。繰り返し要素は()で定義され、タスクは{}で定義されます。この例では、[0]から[11]までの各項目のデータ値を繰り返し表示します。コードは通常、foreachのような関数で構成され、さまざまな種類のタスクを実行します。そのため、ユーザーはソフトウェアで様々なことができるのです。
エラー処理
最後にきれいにしてみましょう。エラーメッセージが表示されることがあるため、100%満足できるものではありません。エラーメッセージは、基本的に、要求したデータ値がEuropeanaのレコードに存在しないために、PHPがEuropeanaのデータを処理できないことを示しているものです。
そのため、あるレコードの画像をクリックすると、正しいウェブサイトに誘導されますが、別のレコードの画像をクリックしても、リンクがないため、そのウェブサイトにたどり着けないことがあります。実際には、私たちのウェブサイトはまだ機能していますが、データが欠けているためにエラーメッセージが表示されることがあるかもしれません。
このチュートリアルで前述したように、データ構造と値は常に一貫しているとは限りません。データ値が利用できない場合には何らかの処理を行う必要があります。これを「例外処理」と呼び、操作に失敗した場合の処理を指定することを意味します。
バグを修正するためには、「データがあるときだけ表示し、ないときは無視する」といった実装が必要です。そのためには、先ほど追加したコードを以下のように置き換えればよいでしょう:
foreach($data_europeana->items as $item) {
print '<td><a href="'.(isset($item->guid)?$item->guid:'').'">' .(isset($item->title[0])?$item->title[0]:'').'</a></td>';
print '<td>'.(isset($item->dataProvider[0])?$item->dataProvider[0]:'').'</td>';
print '<td><a href="'.(isset($item->edmIsShownAt[0])?$item->edmIsShownAt[0]:'').'">View at the provider website</a></td>';
print '<td><a href="'.(isset($item->guid)?$item->guid:'').'"><img src="'.(isset($item->edmPreview[0])?$item->edmPreview[0]:'').'"></a></td></tr>';
}上記は前の例とほぼ同じですが、issetが追加されています。これはPHPの関数で、データがセット(存在)されているかどうかを括弧()のなかでチェックします。さらに、次のように条件分岐を行います。
isset($data)?’$data is set’:‘$data is not set’;この場合、$dataがあれば“$data is set”というテキストが使われ、$dataがなければ”$data is not set”というテキストが使われます。このコードに基づいて、ある条件のタスクを実行することができます。たとえば、テーブルの最初のカラムでは、$item->guidが設定されていれば、それを使います。そうでなければ空のテキスト (“”) が使われます。これで、リンクが正しく機能するようになります。APIからデータが呼び出されるたびに($item->が表示されるたびに)、このパターンのコードを使用します。その結果、うまくいけばエラーメッセージが消えるはずです。
残念ながら、必要なデータが利用可能かどうかを予め知ることができる良い方法というものはありません。というのも、私たちにできるのは、Europeanaに問い合わせをして、そこにあるかどうかを調べるのを待つことだけだからです。この構成は、リクエストにちょっとしたミスがあったとしても、他のすべてを壊すことなく、少なくとも何らかの動きを見せるという利点がありますが、例外やエラーを管理する必要があるという欠点があります。
このチュートリアルでは、すべてのエラーシナリオを扱っているわけではないことに注意しましょう。たとえば、データ ($item->edmIsShownAt[0]) が URL ではないという可能性は考慮していません。なぜなら、このチュートリアルはプログラミングのレッスンではなく、入門編だからです。適切なアプリケーションを開発するためには、PHPプログラミングをより深く掘り下げる必要があります。
おめでとうございます!EuropeanaのAPIデータをカスタマイズして構造化し、シンプルながらも素敵なウェブページを短時間で作成することができました。
APIテンプレート
PHPでのAPIコールを一般化する
最後のセクションでは、先ほど作成したコードを基に、APIテンプレートの作成を試みます。以下のコードは、先ほど作成したコードの中核部分です。テンプレート内のいくつかのパラメータを変更するだけです。いつものように、YOUR_API_KEYは変更する必要があります。VARIABLE1、VARIABLE2、VARIABLE3の名前をより意味のある名前に置き換えることをお勧めします。HTTP(データ型は文字列)はAPIのURLです。ほとんどのAPIでは、前に見たようにHTTPのなかに$apikeyを挿入する必要があります。しかし、他の部分は同じままにするべきです。
$apikey = 'YOUR_API_KEY';
$VARIABLE1 = fopen('HTTP', 'r');
$VARIABLE2 = stream_get_contents($VARIABLE1);
fclose($VARIABLE1);
$VARIABLE3 = json_decode($VARIABLE2);さらに、実際のデータで何をしたいかを調整する必要があります。例えば、以下のコードはデータ検索部分を一般化したもので、foreachだけで配列を処理し、ループでデータ値をprintをします。
foreach($data as $item) {
print 'WHATEVER YOU WANT TO DISPLAY';
}上記の2つのコードを組み合わせることで、さまざまなタイプのJSONデータを操作できるようになります。
Harvard Art Museumsでテンプレートを試してみる
APIテンプレートが実際に他のAPIで動作するか確認してみましょう。ここではハーバード美術館のAPIを使用します。APIのドキュメントをちょっと見てみましょう。いつものように、まずAPIキーを取得する必要があります。
一度理解したら、さっそくウェブブラウザでオブジェクト検索用APIを試してみて、データ構造を理解しましょう。https://api.harvardartmuseums.org/object?apikey=YOUR_API_KEY&keyword=andromeda
レコードはrecords要素の中に配列の形で存在しています。これにより、どのようなデータを取得したいのかがわかります。以下のコードを実行すると、実際にブラウザに何が表示されると思いますか?
<?php
$apikey = 'YOUR_API_KEY';
$contents_harvard = fopen("https://api.harvardartmuseums.org/object?apikey=$apikey&keyword=andromeda", 'r');
$json_harvard = stream_get_contents($contents_harvard);
fclose($contents_harvard);
print($json_harvard);
// For display purposes, <hr> are added several times in this file
print '<hr>';
$data_harvard = json_decode($json_harvard);
print $data_harvard->info->totalrecords;
print '<hr>';
//the next block of code will go here
?>どうやら、新しい名前が「変数」として割り当てられたようです。例えば、$contents_harvardと$json_harvardが使われています。しかし、他はすべて同じように見えているはずです。
準備ができたら、上の例の最後のコメントの下に次のコードを追加してください:
foreach($data_harvard->records as $item) {
print '<td>'.(isset($item->title)?$item->title:'').'</td>';
print '<td>'.(isset($item->dated)?$item->dated:'').'</td>';
print '<td>'.(isset($item->creditline)?$item->creditline:'').'</td>';
print '<td><a href="'.(isset($item->url)?$item->url:'').'">View at the website</a></td>';
print '<td><a href="'.(isset($item->isShownAt)?$item->primaryimageurl:'').'"><img src="'.(isset($item->primaryimageurl)?$item->primaryimageurl:'').'" height="100" width="100"></a></td></tr>';
print '<br>';
}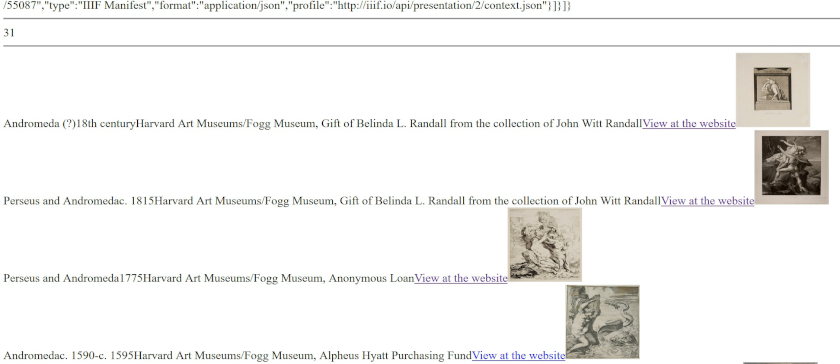
うまくいけば、europeana_api.phpとよく似たものが表示されます。今回は、単に各レコードを<br>(改行)で区切って表示しているだけで、意図的にテーブルを作成していません。このため、結果は整頓されていないように見えますが、これは単にあなたが望むことを何でもできるということを意味しています。ひとつ付け加えるとすれば、<img 要素で画像のサイズをheight=”100″ width=”100″と指定していることです。こうすることで、すべての画像を同じサイズにしています。
ポイントは、APIテンプレートは再利用やカスタマイズが可能だということです。したがって、最も難しいのは、指定されたAPIの根底にあるデータモデルの精査と、データ構造の取り扱いでしょう。それを何とかするためには、APIドキュメントを注意深く読み込む必要があります。また、このテンプレートは魔法のテンプレートではないことにも注意が必要です。典型的なクエリ用のAPIに適用できる、初心者向けのショートカットを提供しているに過ぎません。APIには様々な種類があるので、別のアプローチが必要になるかもしれませんし、疑問があれば常にAPIドキュメントを参照すべきです。
みんなのためのAPI
プログラミングを少し学ぶことができれば、ウェブサイトがデフォルトで提供するものに制限されることはもうありません。例えば、新しい方法でのデータの選択、フィルタリング、比較、処理、分析、可視化、共有など、独自のツールやシステムを自由に構築できるようになるのです。さあ、あなたは何を待っているというのですか?勇気を出して、新しいプロジェクトを始めましょう。
便利なAPI
APIを使った著者自身のプロジェクト
- James Cook Dynamic Journal (JCDJ)…Open Libraryの本の文脈化
- WiQiZi…Wikipedia/DBpediaのゲーミフィケーション
- CAROL…Open Libraryの本を文脈から探る
著者について
Go Sugimotoは、オーストリア科学アカデミーのオーストリアデジタル人文科学センター(ACDH)に勤務するデータアナリスト。Europeanaやオランダ国立公文書館でArchives Portal Europe、フィレンツェ大学のCHIRONフェローシップ(イタリア)、東京国立近代美術館(日本)、Wessex Archaeology(英国)など、世界中の文化遺産プロジェクトで幅広く活躍している。
引用の際はこちらをご利用ください
<原著>
Go Sugimoto, “Introduction to Populating a Website with API Data,” Programming Historian 8 (2019), https://doi.org/10.46430/phen0086.
<翻訳記事>
Go Sugimoto著, 菊池信彦訳. APIデータによるウェブサイトの作成入門. DH研究情報ポータル. 2023. https://dhportal.ac.jp/?p=1582.

この 作品 は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。