Evan Peter Williamson
OpenRefineは、データを探索、クリーニング、変換するための強力なツールです。このレッスンでは、Refineを使用してURLを取得し、Webコンテンツを解析する方法について学びます。
[訳者からのお断り]本レッスン内容は、Evan Peter Williamson, “Fetching and Parsing Data from the Web with OpenRefine,” Programming Historian 6 (2017), https://doi.org/10.46430/phen0065.のうち、Example 3(事例3)を除いた抄訳です。
目次
レッスンの目標
OpenRefineはデータを探索、クリーニング、変換するための強力なツールです。Programming Historianの既存のレッスン「OpenRefineでデータをきれいにする方法」では、データセット内の不整合を効率的に発見し、修正するためのRefineの基本的な機能を紹介しました。このレッスンでは、このようなデータ操作に不可欠なスキルをベースに、URLの取得とWebコンテンツの解析を行うRefineの機能に焦点を当てています。事例では、次のようなデータセットの変換や充実化のための高度な機能の一部を紹介します。
- Refineを使用してURLを取得
- シンプルなウェブAPIから情報を取得するためのURLクエリを構築する
- HTMLとJSONレスポンスを解析して関連データを抽出する。
- 配列関数を使用して文字列値を操作する
- Jythonを使ってRefineの機能を拡張する
OpenRefineやHTML、変数やループなどのプログラミングの概念について基本的な知識があると、このレッスンに役立ちます。
なぜOpenRefineを使うのか?
ウェブ上で利用可能な非構造化文書からデータセットを作成する能力は、デジタル化一次資料、ウェブアーカイブ、テキスト、現代のメディアストリームを使った研究可能性を開くものです。Programming Historian のレッスンでは、このようなコンテンツを集めて扱う、wgetからPythonまで、多くの方法を紹介しています。 テキスト文書を扱う場合、Refineは特にこの作業に適しており、ユーザはURLを取得し、インタラクティブかつ探索的な方法で、その取得結果を直接処理することができます。
Freebase Gridworks(2009年)の開発者であるDavid Huynhは、Refineを次のように説明しています。なお、Freebase Gridworksは、2010年にGoogleRefineに、2012年以降はOpenRefineと名を変えています。
- スプレッドシートより強力
- スクリプトよりもインタラクティブで視覚的
- データベースよりも一時的/探索的/実験的/遊び心があるもの[1]
Refineは、データベースとスクリプト言語のパワーを、インタラクティブでユーザーフレンドリーなビジュアルインターフェースに統合したユニークなツールです。この柔軟性により、Refineはジャーナリスト、図書館員、科学者など、多様なソースやフォーマットからなるデータを、構造化された情報にまとめる必要のある人々に受け入れられています。
OpenRefineはフリーでオープンソースのJavaアプリケーションです。ユーザーインターフェースはウェブブラウザによってレンダリングされますが、Refineはウェブアプリケーションではありません。情報はオンラインで送信されず、インターネット接続も必要ありません。完全なドキュメントは公式wikiにあります。Refineのインストール方法と使い方については、こちらのワークショップページをご覧ください。
注:このレッスンはopenrefine-2.7を使って書かれました。ほとんどすべての機能はバージョン間で互換性がありますが、最新のバージョンを使うことをお勧めします。
レッスン概要
このレッスンでは、ウェブからデータを取得して処理するワークフローを3つの事例をもとに紹介します。
- 事例1:HTMLの取得と解析では、HTMLを解析し、文字列配列関数を使用することで、電子書籍を構造化データセットに変換します。
- 事例2: URL クエリと JSON の解析では、シンプルな Web API と対話し、新聞史料の一面のフルテキストデータセットを構築します。
- 事例3: 高度なAPIは、自然言語処理ウェブサービスへのPOSTリクエストの実装手法について、Jythonを使いながら示します。[訳註:この事例3は訳出していません。]
事例1:HTMLの取得と解析
この例では、Refineの組み込み関数を使用して、1つのウェブページをダウンロードし、構造化テーブルへと解析します。同様のワークフローを、別のWebページを解析することによって生成されるURLのリストに適用することで、柔軟なWeb収集ツールを作成することができます。
この例の生データは、Project Gutenbergのシェイクスピアの『ソネット』のHTMLコピーです。詩を構造化データに加工することで、テキストの新しい読み方が可能になりますし、ソートや操作、他の情報と結びつけることができるようになります。
注意:Project Gutenbergは、カタログデータを一括ダウンロードするためのフィードを提供しています。Project Gutenbergの公開ウェブサイトは、ウェブスクレイピング目的では使用しないでください。この例では、Gutenbergサイトへのリダイレクトを避けるため、HTML版電子書籍のコピーをGitHubにおいています。
「ソネット」プロジェクトを始める
OpenRefineを起動し、新規プロジェクトを選択します[訳註:本稿ではOpenRefineの画像をすべて日本語インターフェースに差し替えています。そのため、画像は翻訳時の最新バージョンであるver. 3.7.5です]。Refineは、ローカルのExcelファイルからウェブでアクセス可能なRDFまで、様々なフォーマットやソースからデータをインポートすることができます。よく見落とされがちな方法として、コピー&ペーストでデータを入力できるクリップボードがあります。「データを取得する」の下にあるクリップボードをクリックし、次のURLをテキストボックスに貼り付けます:
https://programminghistorian.org/assets/fetch-and-parse-data-with-openrefine/pg1105.html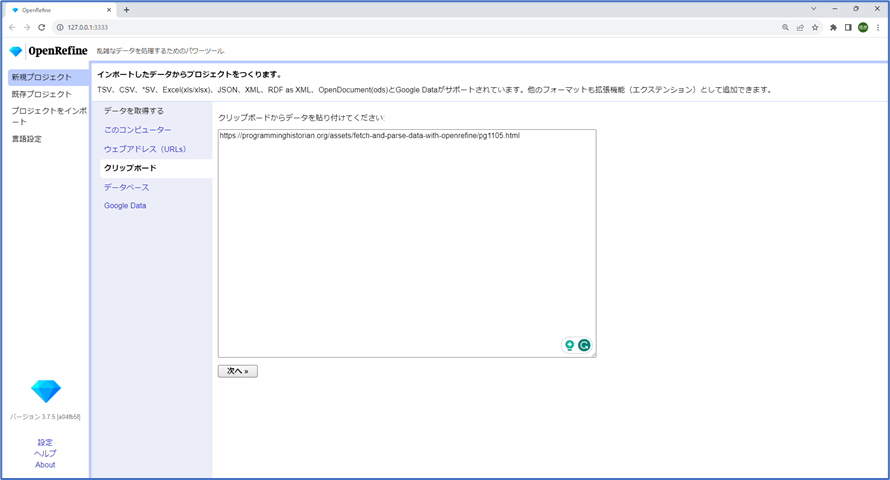
次へをクリックすると、Refineが自動的にコンテンツを行ベースのテキストファイルとして認識し、デフォルトの解析オプションが正しく設定されるはずです。右上の「名」[訳註:デフォルトで「クリップボード」と入力されています]のところにプロジェクト名「Sonnets」を追加し、プロジェクトを作成をクリックします。これで、1列1行のプロジェクトができあがります。
HTMLを取得する
Refineの組み込み機能でURLのリストを取得するには、新しいカラムを作成します。カラム1のメニュー矢印をクリック > カラム編集 > URLでカラムを追加…をクリックします。
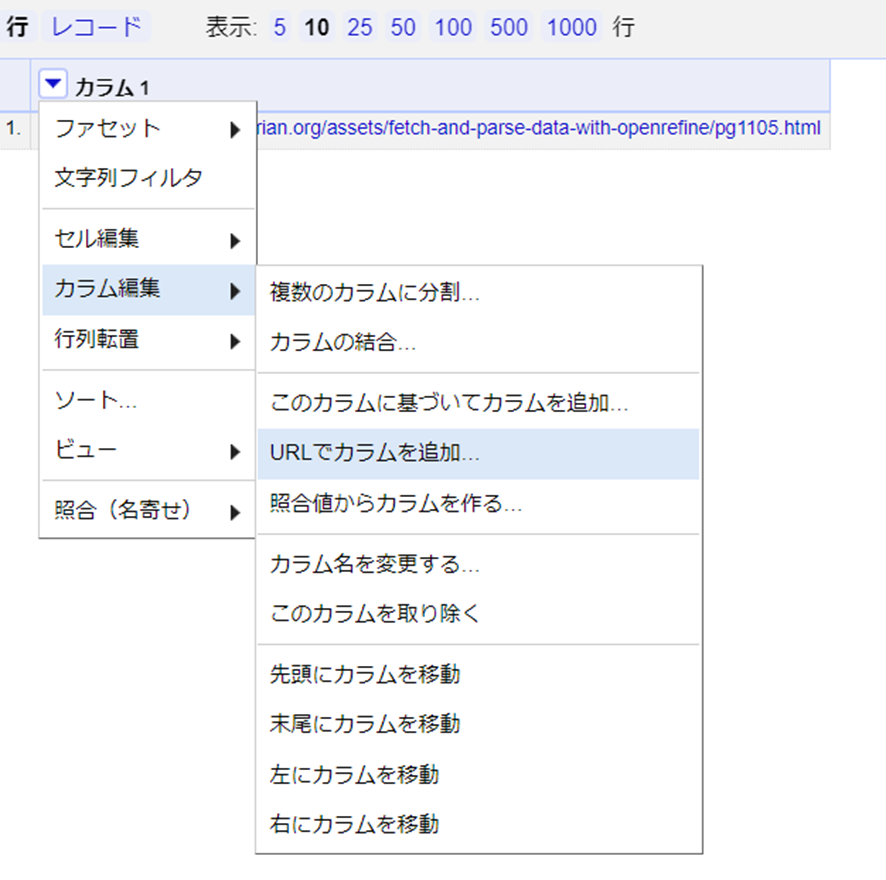
新しいカラムに”fetch”という名前を付けます。フェッチ間隔のオプションは、サーバーにブロックされるのを避けるために、リクエスト間の休止時間を設定します。デフォルトは控えめに設定されています。
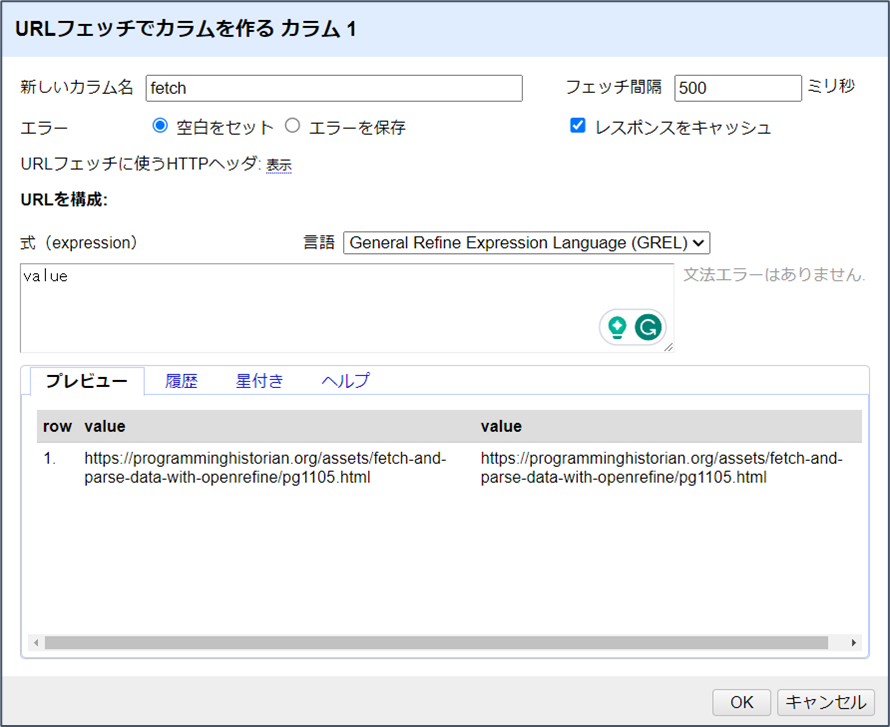
「OK」をクリックすると、Refineはブラウザでページを開くのと同じように、ベースカラムからURLのリクエストを開始し、各レスポンスを新しいカラムのセルに保存します。この場合、カラム1に1つのURLがあることから、fetchと名付けたカラムの1つのセルにSonnetsウェブページの完全なHTMLソースが格納されます。
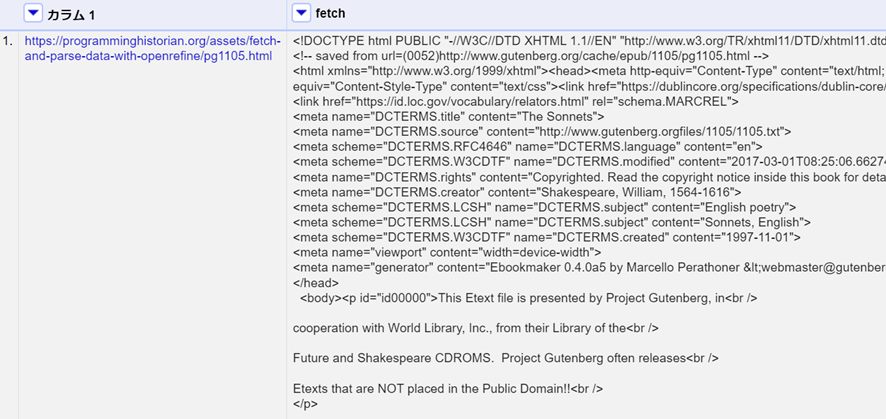
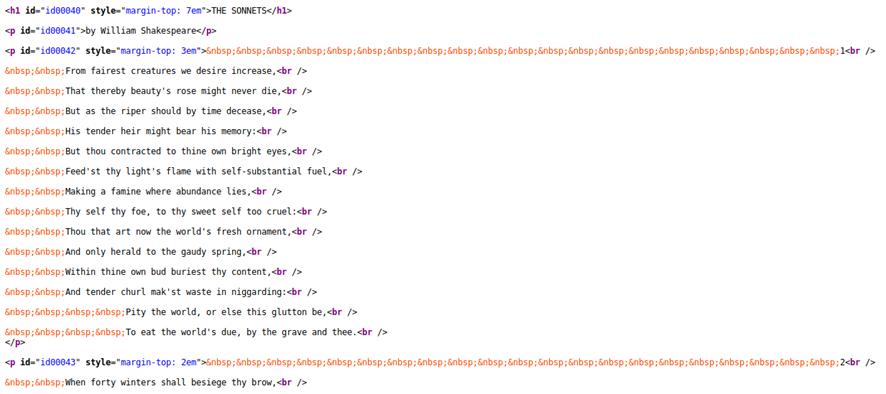
HTMLを解析する
取得したウェブページの多くはソネット(14行詩)のテキストではないので、きれいなデータセットを作るためにはそれらを削除しなければなりません。まずは、目的としているコンテンツを分離できるようなパターンを特定する必要があります。アイテムは、多くの場合、一意となるコンテナに入れられたり、意味のあるクラスやIDが与えられていたりします。
HTMLを調べやすくするために、カラム1のURLをクリックしてリンクを新しいタブで開き、ページ上で右クリックして「ページのソースを表示」してください。この場合、ソネットのページには特徴的なセマンティックマークアップはありませんが、一つ一つの詩はそれぞれ<p>要素の中に含まれています。したがって、すべての段落[訳註:<p>のこと]を選択すれば、グループからソネットのみを抽出することが可能です。
fetchカラムで、メニュー矢印 > カラムの編集 > このカラムに基づいてカラムを追加…をクリックします。新しいカラムに “parse “という名前を付け、式(expression)のテキストボックスをクリックします。
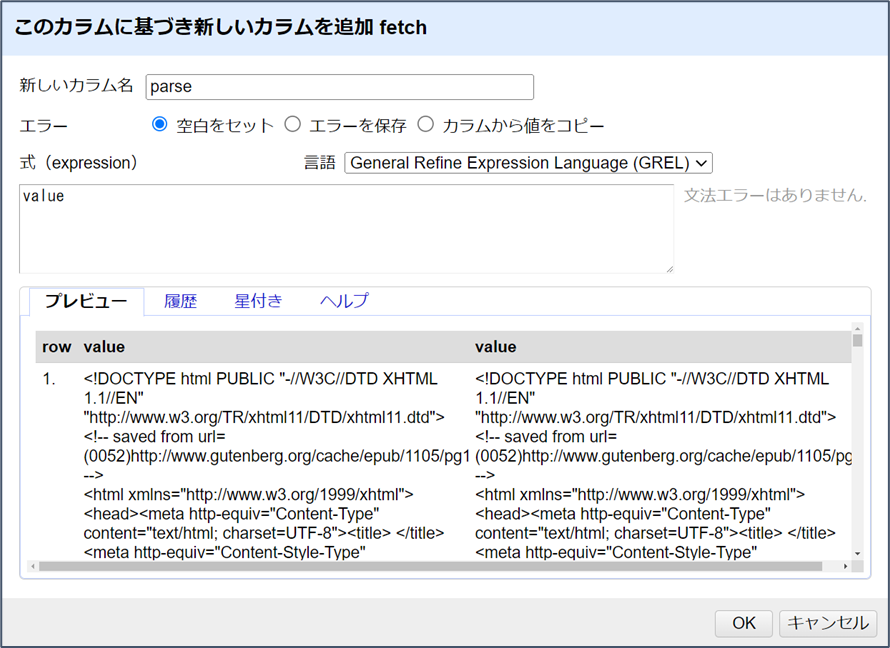
Refineのデータは、General Refine Expression Language (GREL) を使って変換することができます。式(expression)ボックスは、既存のカラムの各セルに適用されるGREL関数を受け入れ、新しくカラムの値を作成します。式(expression)ボックスの下にあるプレビューウィンドウには、左側に現在の値、右側に新しく作られるカラムの値が表示されます。
デフォルトの式はvalueで、これはセルの現在の内容を表すGREL変数です。これは、各セルが単に新しい列にコピーされ、それがプレビューに反映されるということを意味します。GRELの変数と関数は、ドット記法と呼ばれるピリオドを使って順番につなぎ合わされます。これにより、各関数の結果を次の関数に渡すことで、複雑な演算を行うことができるのです。
GRELのparseHtml()関数はHTMLコンテンツを読み込むことができ、select()関数と jsoupセレクタ構文を使って、要素にアクセスできるようになります。valueから始めて、Expressionボックスにドット記法でparseHtml()とselect("p")関数を追加してみましょう。すなわち、次のように記述します。
value.parseHtml().select("p")この時点ではOKをクリックせず、単にプレビューを見て式の結果を確認します。
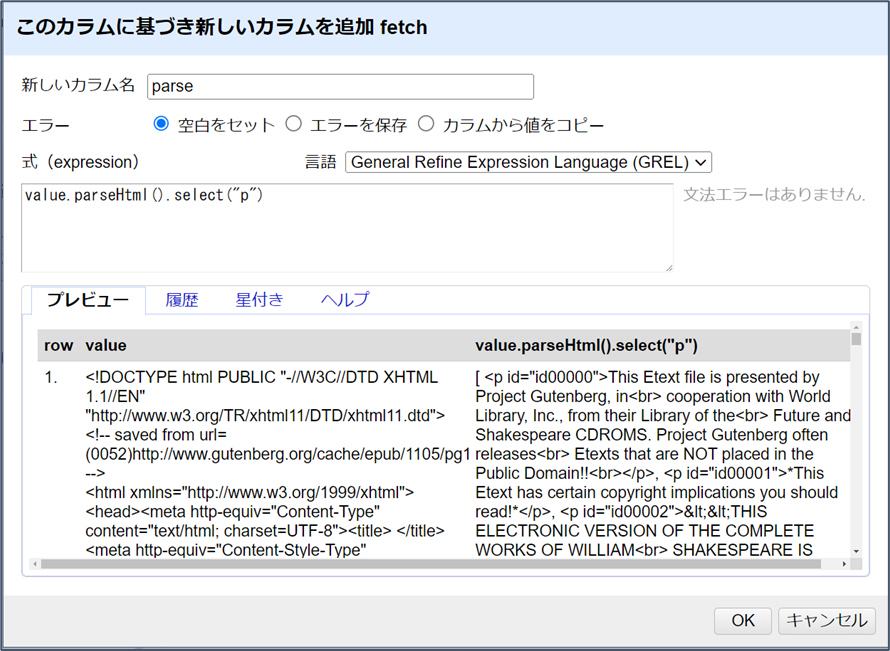
右側の出力は、左側で見たHTMLのルート要素(<!DOCTYPE htmlなど)で始まらなくなっていることに注目してください。代わりに角括弧[で始まり、ページ内で見つかったすべてのp要素の配列が表示されます。Refineは、配列を角括弧で囲まれたカンマ区切りのリストとして表現します。つまり、[ "one", "two", "three" ]という形です。
Refine は視覚的で反復的です。プレビューで結果を確認しながら、徐々に式を構築していくのが一般的です。GRELのデバッグに役立つだけでなく,関数を追加する前にデータセットについてより深く知ることができます.OKをクリックせずに、Expressionボックスで次のGRELステートメントを試してみてください。プレビューウィンドウを見て、それらがどのように機能するかを理解してください:
- 例えば、
value.parseHtml().select("p")[0]のように、式にインデックス番号を加えることで、配列から1つの要素を選択することができます。ソネットファイルの冒頭には、データセットには不要なライセンス情報の段落が多数含まれています。それらのインデックス番号を飛ばして、最初のソネットを表示するには、value.parseHtml().select("p")[37]となります。 - GRELは負のインデックス番号の使用もサポートしているので、
value.parseHtml().select("p")[-1]は配列の最後の項目を返します。後ろから数えると、最後のソネットはインデックス[-3]となります。 - これらのインデックス番号を使って配列をスライスし、ソネットを含む
pの範囲のみを抽出することができるようになります。slice()関数を式に追加してvalue.parseHtml().select("p").slice(37,-2)とし、サブセットをプレビューしてみましょう。
上記の式でOKをクリックすると、空白のカラムになります。これは、配列を扱うときによくある混乱の原因です。Refineは、配列オブジェクトをセルの値として保存しません。配列を文字列変数に変換するには、toString() または join() を使用する必要があります。join() 関数は、指定した区切り文字で配列を連結します。たとえば、[ "one", "two", "three" ].join(";") という式は、”one;two;three” という文字列になります。したがって、parseカラムを作成する最終的な式は次のようになります。
value.parseHtml().select("p").slice(37,-2).join("|")OKをクリックして、式を使用して新しいカラムを作成してください。
変換をテストして何が起こるかを確認しますが、元に戻すのはとても簡単です!操作の全履歴は「取り消す/やり直す」タブに記録されています。
セルを分割する
parseカラムには”|”で区切られたソネットが含まれていますが、プロジェクトにはまだ1行しかありません。セルを分割することで、各ソネットの個別の行を作成することができます。parseカラムのメニュー矢印をクリックし > セル編集 > 多値のセルを分割…をクリックします。先ほどの最後のステップでのjoinに使った、セパレーター「|」を入力してください。
この操作の後、プロジェクト・テーブルの上部に154行と表示されます。この数字の下にある、「モード:行 レコード」で切り替えができます。レコードをクリックすると、元のテーブルに基づいて行がグループ化され、この場合は1と表示されます。Refineでデータを変換する際、これらの数字を追跡しておくことは、重要な「整合性チェック」になります。154行は、電子書籍に154のソネットが含まれていることを意味し、1レコードは1行しかない元のテーブルを表しています。予期せぬ数値は、変換に問題があることを示しています。
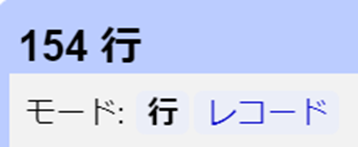
parseカラムの各セルには、<p>タグで囲まれたソネットが1つ含まれています。このタグはHTMLを再度解析することできれいにすることができます。Parseカラムをクリックし、セルの編集>変換…を選択します。新しいカラムを作成するのと同じようなダイアログボックスが表示されます。しかし、変換は新しいカラムの作成ではなく、現在のカラムのセルを上書きするものです。
式(expression)ボックスにvalue.parseHtml()と入力します。プレビューでは、<html>要素から始まる完全なHTMLツリーが表示されます。parseHtml()は、有効なHTML文書でないにもかかわらず、これらのセル値を解析できるように、欠落しているタグを自動的に埋めるので十分注意してください。次に、pタグを選択し、インデックス番号を追加し、関数innerHtml()を使ってソネットのテキストを抽出します。
value.parseHtml().select("p")[0].innerHtml()OKをクリックして、カラムにある154個のセルをすべて変換します。
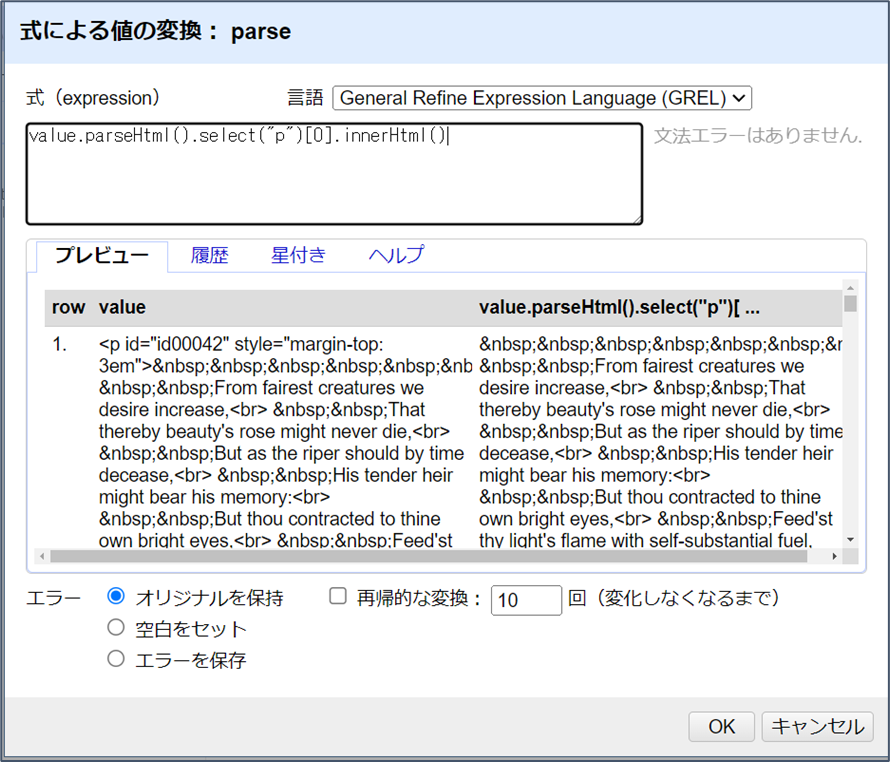
上の式では、selectは、各セルに1つしかないにもかかわらず、p要素の配列を返しています。その配列をinnerHtml()に渡そうとするために、エラーが発生します。したがって、innerHtml()に正しいオブジェクト・タイプを渡すには、配列の最初の(そして唯一の)項目を選択するためのインデックス番号が必要だったのです[訳註:[0]を挿入した理由です]。
GREL式をデバッグする際には、データ・オブジェクトの型に注意してください!
Unescape関数
各セルには多くの があることに気づくでしょう。これは、ブラウザがソース中の余分な空白を無視するために、「改行禁止のスペース(NBSP)」を表現するために使用されるHTMLエンティティです。これらのエンティティはウェブページをハーベスティングするときによく使われるもので、unescape()関数を使えば対応するプレーン・テキスト文字にすぐに置き換えることができます。parseカラムで、セル編集 >変換…を選択し、式ボックスに次のように入力します。
value.unescape('html')NBSPエンティティは通常の空白に置き換えられます。
配列関数で情報を抽出する
GRELの配列関数は、テキストデータを操作する強力な方法を提供し、ソネットの処理の完了まで使えるものです。任意の文字列値は、項目を区切っている文字または式を指定することで、split() 関数を使って配列に変換することが可能です。(これは基本的にjoin()とは逆の操作になります。)
ソネットの各行は<br>で終わっているため、分割するのに便利な区切り文字となっています。value.split("<br>")の式は、各ソネットの行の配列を作成します。インデックス番号とスライスを使用して、新しいカラムを作成することができます。Refineは配列を直接セルに出力しないことに注意してください。必ずインデックス番号を使って配列から1つの要素を選択するか、join()で文字列に変換しなおしてください。
さらに、ソネットのテキストには、電子書籍で詩をレイアウト表示するために使われた不要な空白が大量に含まれています。これはtrim()関数を使って各行からカットすることができます。trim関数は、セル内の先頭と末尾の空白を自動的に削除するもので、データクリーニングの基本です。
これらをもとに、1行を抽出し、トリミングして、ソネット番号と最初の行を表示するきれいなカラムを作成することができます。これらの名前と式を使って, parseカラムから2つの新しいカラムを作成します[訳註:parseカラムの▽から、カラム編集 > 子のカラムに基づいてカラムを追加…をクリックします]。
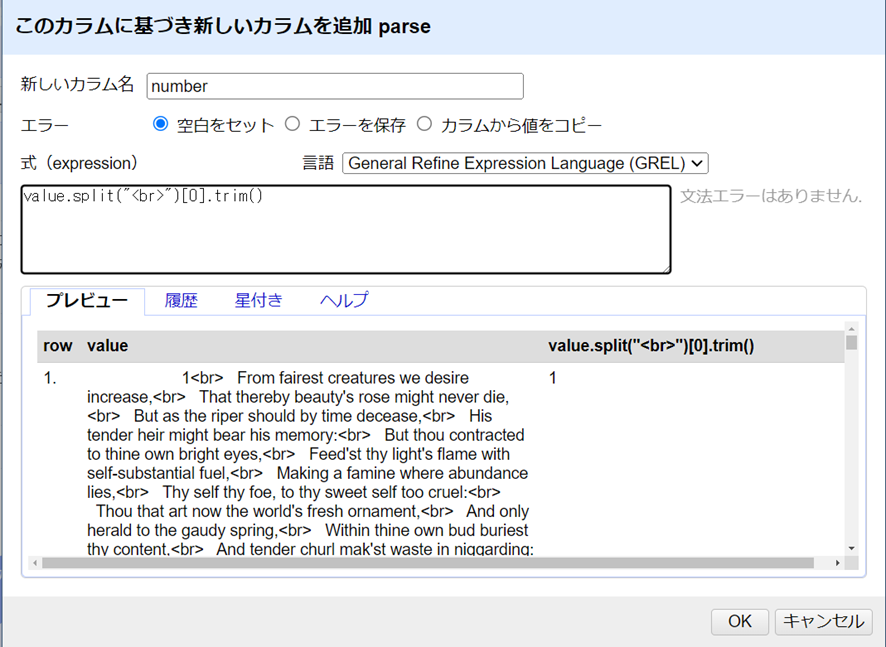
- “number”,
value.split("<br>")[0].trim() - “first”,
value.split("<br>")[1].trim()
次に作成する列は、複数行からなるソネット全体のテキストです。しかし、trim() はセルの最初と最後だけをきれいにするので、ソネット本文にある不要な空白が残ったままです。各行から個別に空白を除去するには、GRELコントロールのforEach()を使用します。forEach()は、配列を繰り返し処理する便利なループです。
parseカラムから、”text”という新しいカラムを作成し、式ボックスをクリックします。forEach()文は、配列、変数名、変数に適用される式が必要です。forEach(配列, 変数, 式)の形式に従って、以下のパラメータを使用してループを構築していきましょう。
- array:
value.split("<br>")。これにより、各セルのソネットの行から配列を作ります。 - variable:
line。配列の各項目が変数として表現されます(何でも構いませんが、vがよく使われます)。 - 式:
line.trim()。各項目は指定された式で個別に評価されます。この場合、trim()は配列の各ソネット行から空白を取り除きます。
この時点で、Expressionボックスの文は、forEach(value.split("<br>"), line, line.trim())となるはずです。プレビューでは、最初の要素がソネット番号である配列が表示されていることに注意してください。forEach()の結果は新しい配列として返されるので、sliceやjoinなどの配列関数を追加することができます。slice(1)を追加してソネット番号を削除し、join("\n")を追加して行を連結して文字列値にします(\nはプレーンテキストの改行を表す記号です)。このように、ソネットの全文を抽出してきれいにする最終的な式は次のようになります。
forEach(value.split("<br>"), line, line.trim()).slice(1).join("\n")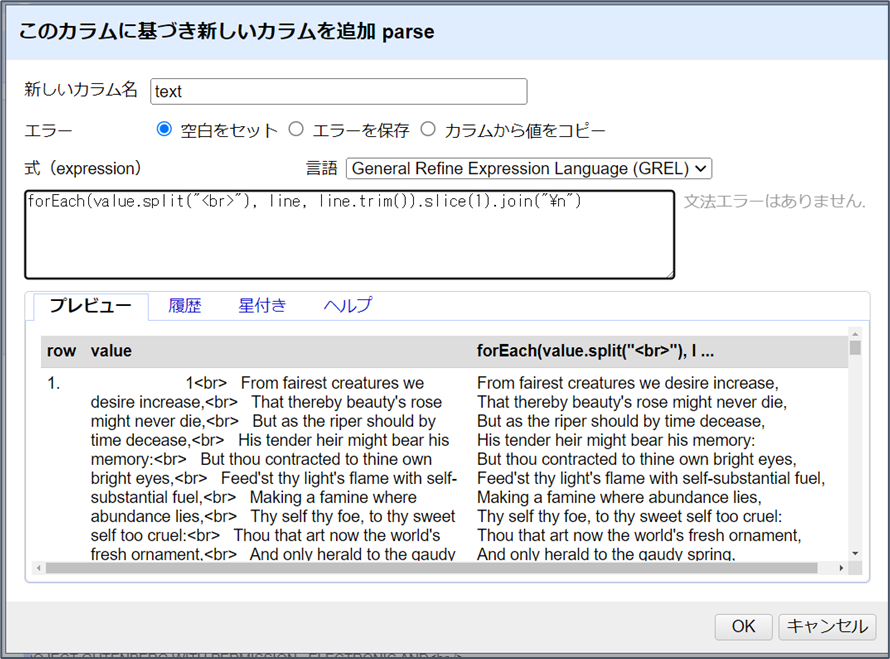
「OK」をクリックしてカラムを作成します。同じ要領で、parseカラムから “last”という名前で、最後の対句行を表す新しいカラムを追加します。
forEach(value.split("<br>"), line, line.trim()).slice(-3).join("\n")最後に、length() 関数を使用して数値カラムを追加することができます。以下の名前と式で、textカラムから新しいカラムを作成します:
- 新しいカラム名”characters”: 式(expression)
value.length() - 新しいカラム名”lines”: 式(expression)
value.split(/\n/).length()
クリーンアップとエクスポート
この例では、クリーンなデータで新しいカラムを作成するために、いくつかの操作を実行しました。これは典型的なRefineのワークフローであり、各変換を既存のデータと簡単に照合することができます。この時点で不要なカラムは削除することができます。カラムの「全て」をクリック > カラムを編集 > カラムの並べ替え・削除…をクリックします。
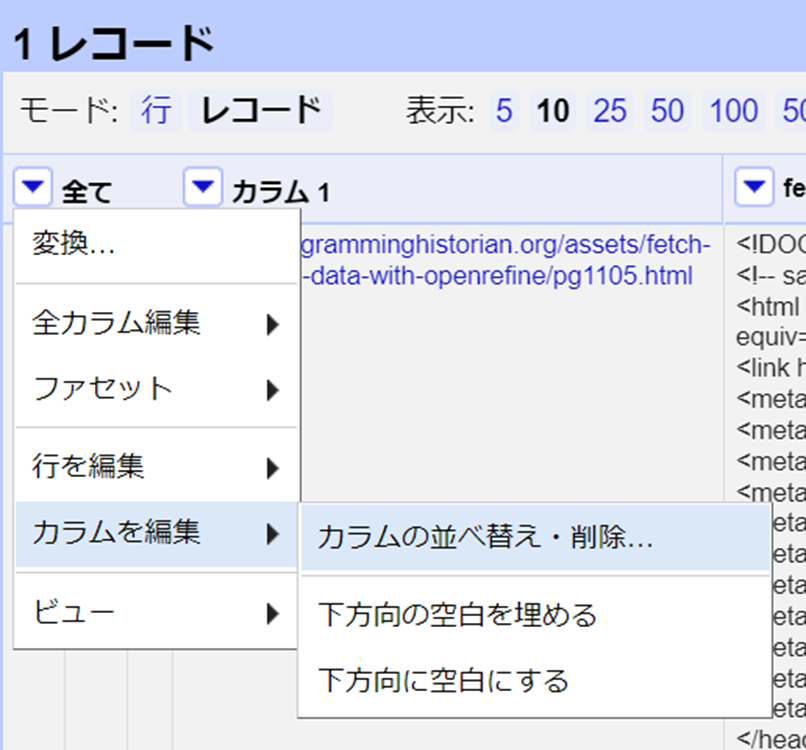
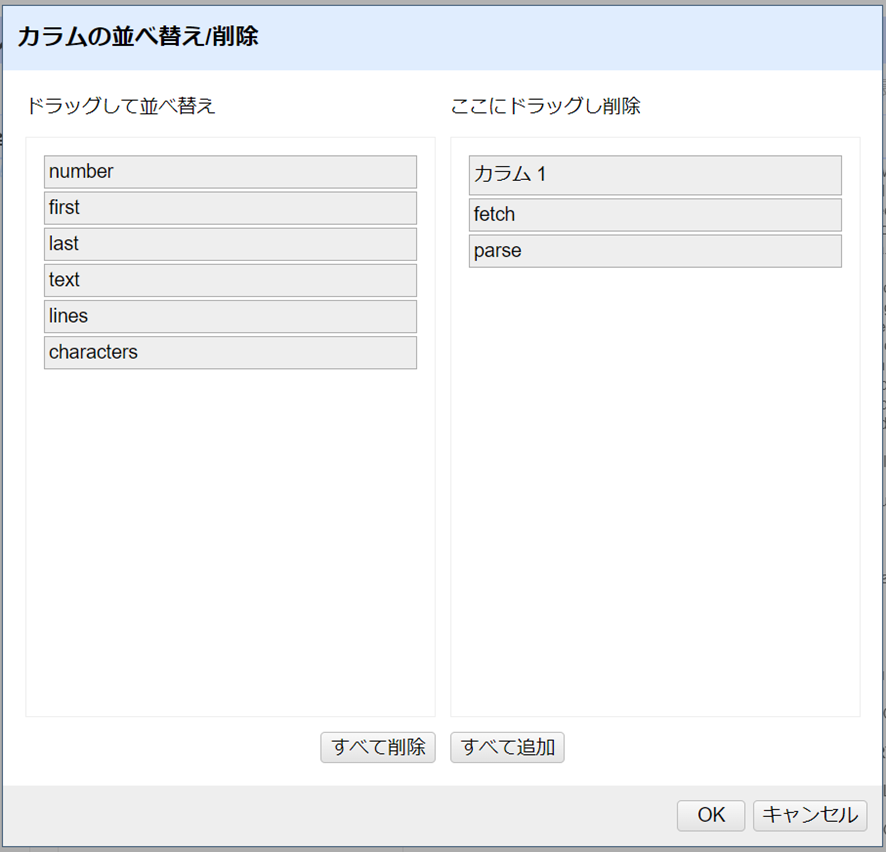
不要なカラム名をダイアログボックスの右側にドラッグします。この場合はカラム1、fetch、parseです。残りのカラムを左側で希望の順番にドラッグして移動させます。OKをクリックしてデータセットを削除し、並び替えます。
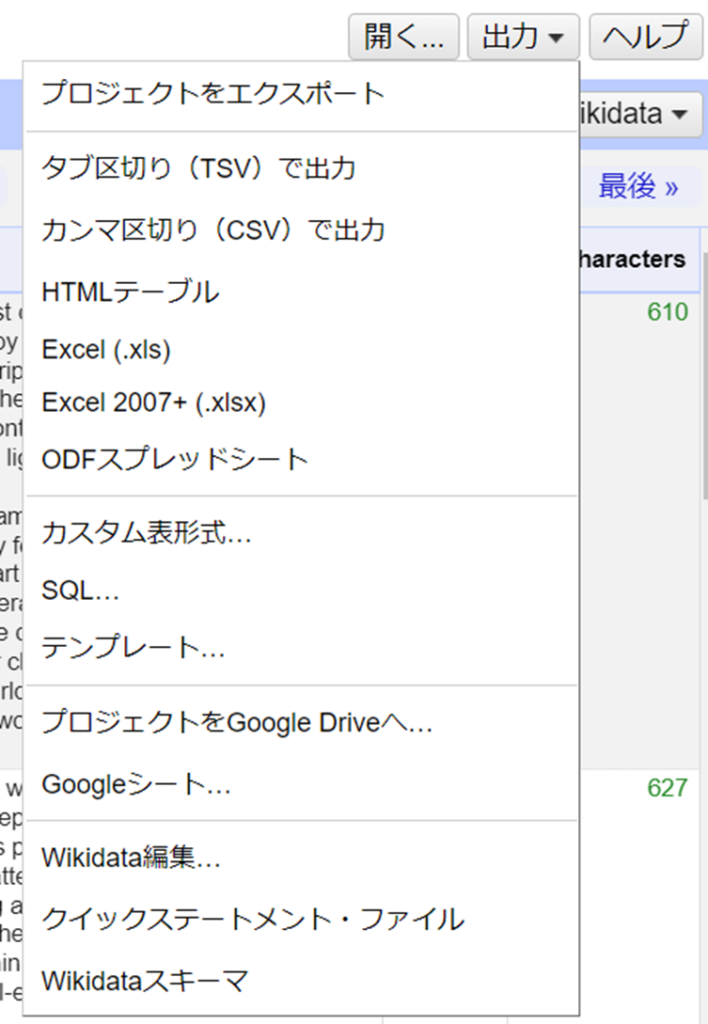
フィルターやファセットを使って、ソネットのコレクションを探索し、サブセット化します。「出力」ボタンをクリックすると、ソネットテーブルが作成されます。現在選択されているサブセットのみがエクスポートされます。
事例2:URLクエリとJSONの解析
多くの文化機関がウェブAPIを提供しており、ユーザは簡単なHTTPリクエストでコレクション情報にアクセスすることができます。これらのAPIによって、以前は不可能だった新しいクエリやテキストの集約を可能にし、リポジトリやコレクションの境界を越えて、コンテンツとメタデータの両方の大規模な分析をサポートするようになっています。この例では、Chronicling Americaプロジェクトからデータを取得し、フルテキストを含む新聞一面のページから、小さなデータセットを作っていきます。一般的なWebスクレイピングのワークフローに従って、Refineを使用してクエリURLを作成し、情報を取得し、そしてJSONレスポンスを解析します。
Chronicling Americaは完全にオープンであるため、APIにアクセスするためのキーやアカウントは必要なく、利用の制限もありません。他のアグリゲータは、多くの場合、独自に開発され、制限されています。ウェブスクレイピングや研究に情報を使用する前に、利用予定のAPIの利用規約を確認してください。
Chronicling Americaプロジェクトを始める
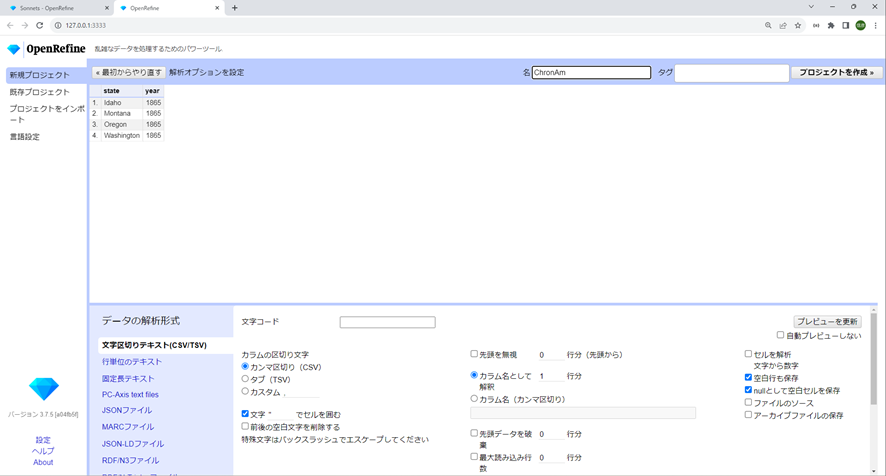
前章の例1を完了した後、この例2のプロジェクトを始めるには、右上の「開く…」ボタンをクリックします。新しくタブが開き、Refineの新規プロジェクトビューが表示されます。先ほどのSonnetsプロジェクトのタブは開いたままでもパフォーマンスに影響はありません。[データを取得するの下にある]クリップボードを選択し、以下のCSVをテキストボックスに貼り付けてから、プロジェクトを作成します。
state,year
Idaho,1865
Montana,1865
Oregon,1865
Washington,1865次へをクリックすると、Refineは自動的にコンテンツを正しい解析オプションを持つCSVとして識別します。右上にプロジェクト名 “ChronAm “追加し、プロジェクトを作成をクリックします。
クエリを作る
Chronicling AmericaはAPIとURLパターンのドキュメントを提供しています。これら正式な文書に加えて、代替フォーマットや検索APIに関する情報が、ウェブページの<head>要素のなかに書かれていることもあります。<link rel="alternate"、<link rel="search"、または<!--のコメントをチェックすると、サイトとやり取りする方法についてヒントが書かれている場合があります。ヒントは、公開リンクを使ってサーバとやりとりするためのレシピブックになります。
ChromAm API の基本コンポーネントは以下の通りです。
- ベースURL:
https://chroniclingamerica.loc.gov/ - 各新聞ページの検索サービスのための場所:
search/pages/results - クエリ文字列:
?で始まり、&で区切られた値のペア(fieldname=value)で構成される。詳細検索フォームを使うのと同じように、クエリ文字列の値のペアが検索オプションを設定します。
GREL式を使い、これらの部品を”ChronAm”プロジェクトの値と組み合わせることで、検索クエリURLを構築することができます。データテーブルの中身にはGREL変数を用いてアクセスができます。事例1で紹介したように、現在のカラムの各セルの値はvalueで表わされています。同じ行の値は、cells変数とカラム名を使って取り出すことができます。cells文の書き方には2つ通りあり、スペースを含むカラム名を許容するブラケット記法cells['column name'].valueと、1単語のカラム名のみを許容するドット記法cells.column_name.valueです。
GRELでは、文字列はプラス記号を使って連結ができます。例えば、"one" + "two"という式は “onetwo”となります。
検索クエリの塊を作るには、stateカラムから、次の式で “url “というカラムを追加します[訳註:stateカラムの▽をクリックし、カラム編集>このカラムに基づいてカラムを追加…をクリック]。
"https://chroniclingamerica.loc.gov/search/pages/results/?state=" + value.escape('url') + "&date1=" + cells['year'].value.escape('url') + "&date2=" + cells['year'].value.escape('url') + "&dateFilterType=yearRange&sequence=1&sort=date&rows=5&format=json"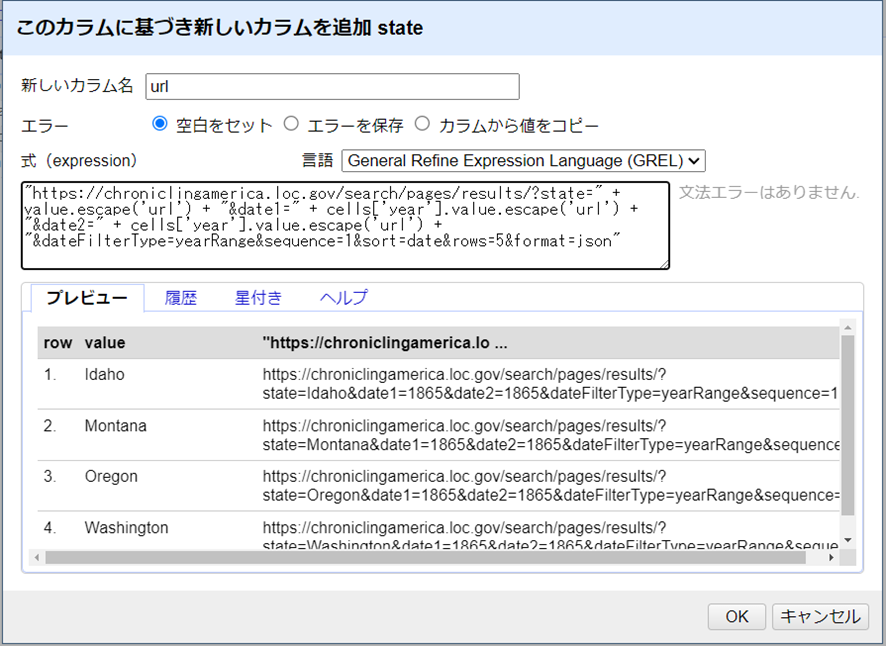
この式は、定数(ベースURL、検索サービス、クエリフィールド名)と各行の値を連結しています。escape()関数は、文字列がURLの中で安全であることを保証するためにセル変数に追加されています(例1で導入されたunescape()関数の反対)。
?の後の値のペアを見て、検索のパラメータを理解しましょう。最初のクエリURLは、以下の条件で新聞史料を検索するものです。
- アイダホ州: (
state=Idaho) - 1865年以降:(
date1=1865&date2=1865&dateFilterType=yearRange) - 一面だけ:(
sequence=1) - 日付によるソート:(
sort=date) - 最大5つを返す:(
rows=5) - JSON形式:(
format=json)
URLの取得
urlカラムは、ブラウザでアクセス可能なウェブクエリのリストです。テストするには、リンクの1つをクリックしてください。urlは新しいタブで開き、JSONレスポンスを返します。
urlカラムで、カラム編集>URLでカラムを追加…を選択し、URLを取得します。新しいカラムに”fetch”という名前を付け、OKをクリックしてください。しばらく待つと操作が完了し、fetchカラムがJSONデータで満たされます。
JSONを解析してアイテムを取得する
クエリのレスポンス結果の最初の名前と値のペアは、"totalItems": 52, "endIndex": 5となっています。 これは、検索結果は合計52件だったが、レスポンスには5件しか含まれていないことを示しています(rows=5のオプションによって制限されたため)。JSONのキーであるitemsには、検索によって返された個々の新聞の配列が含まれています。整然としたデータセットを構築するには、JSONを解析し、各新聞をそれぞれの行に分割する必要があります。
GRELのparseJson()関数では、キーを選択すると、それに対応する値を取得することができます。fetchカラムを基に、新しいカラムを”items”という名前で追加して、次の式を入力します。
value.parseJson()['items'].join("^^^")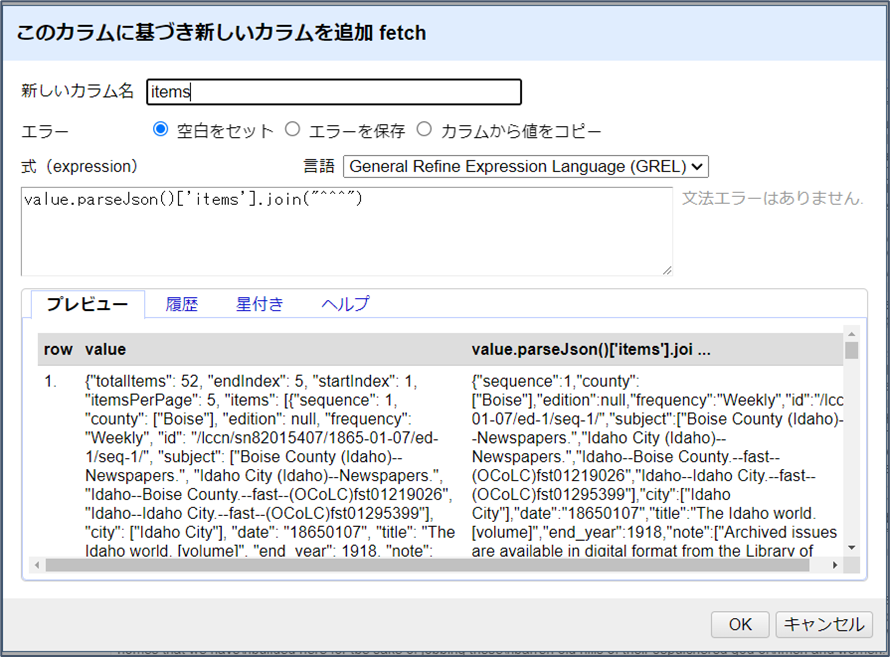
['items']を選択することで、JSONレスポンスの中にある新聞レコードの配列が表示されます。join()関数は、指定されたセパレーターで配列を連結し、文字列値を生成します。新聞レコードにはOCRテキストフィールドが含まれているので、一意であることを保証し、値を分割するために使用できる、一風変わったセパレータ “^^^” が必要でした。
多値セルの分割
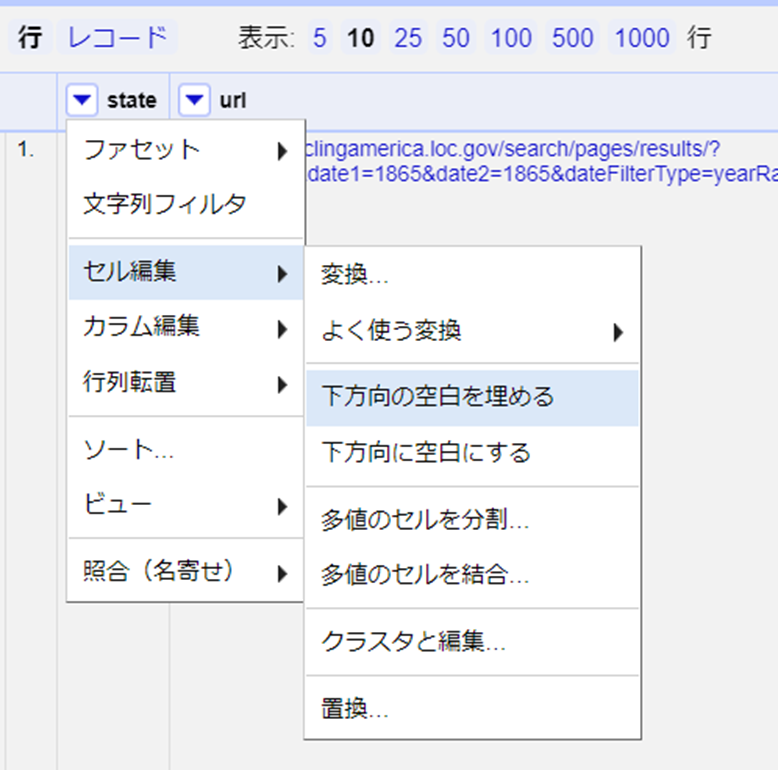
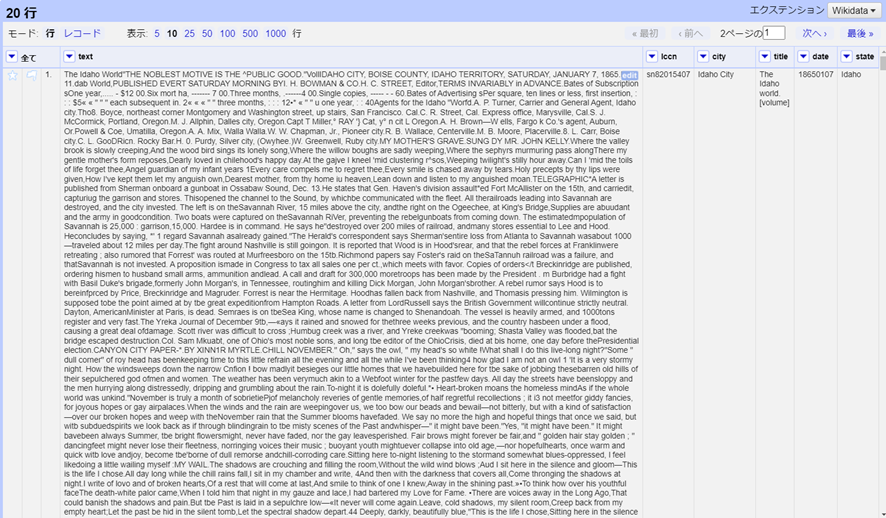
個々の新聞が分離された状態で、セルを分割することで別々の行を作成できます。itemsのカラムで、セル編集 > 多値セルを分割を選択し、先ほど使用した結合用の^^^を[区切り文字のスペースに]入力します。すると、プロジェクト・テーブルの上部に20行と表示されます。「モード:レコード」をクリックすると、元のCSVの行数を示す4と表示されます。
新しく作った行は、items以外のすべてのカラムが空欄であることに注意してください。新聞の各号で、発行された州の情報を確実に入手できるようにするためには、「下方向の空白を埋める」(Fill down)機能を使って空の値を埋める必要があります。stateのカラムをクリック > セル編集 > 下方向の空白を埋めるをクリックします。
ここで、不要なカラムを整理する良いタイミングです。全てのカラム>カラムの編集>カラムの並べ替え・削除…をクリックします。stateとitems以外の列を右側にドラッグし、OKをクリックして削除しましょう。
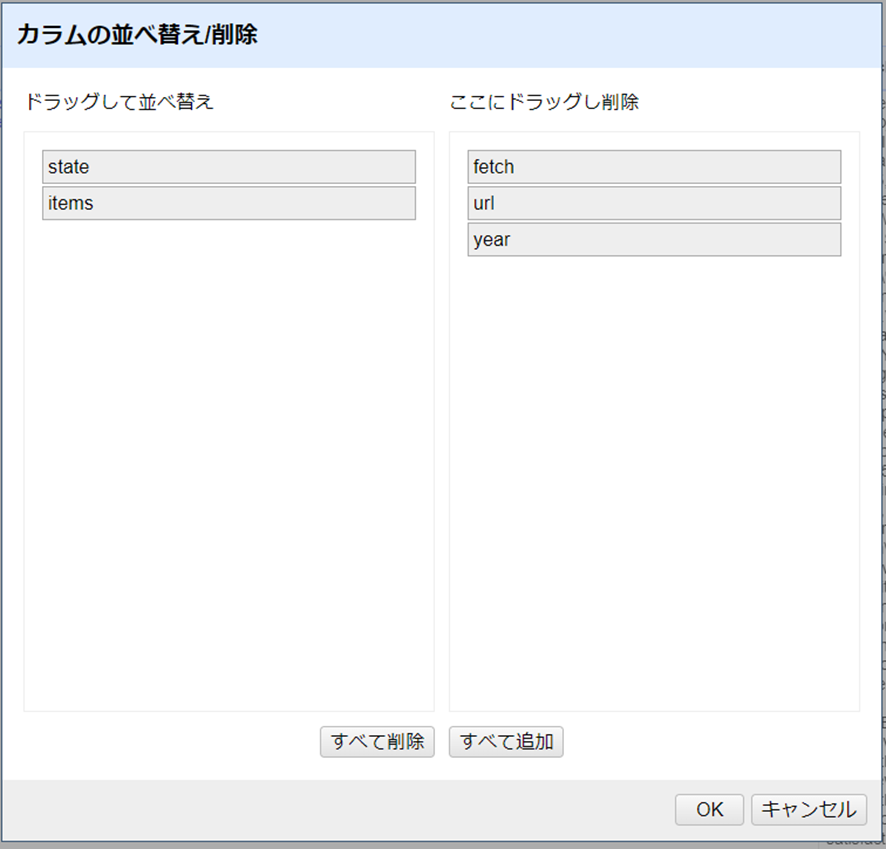
整合性チェック:元のカラムを削除すると、レコードと行の両方が20になります。これは、プロジェクトが4つの州[訳註:Idaho, Montana, Oregon, Washingtonの4つのこと]で始まり、それぞれ5つのレコードを取得したことから、正しいことが確認できます。
JSON値の解析
データセットを完成させるには、各新聞のJSONレコードを個々のカラムに解析する必要があります。多くのウェブAPIはJSON形式で情報を返すので、これは一般的な作業となります。ここでも、GRELのparseJson()関数を使うと簡単です。JSONを解析してキーを選択し、itemsのカラムをもとに、各新聞のメタデータ要素から新しいカラムを作成します。[訳註:itemsのカラムで「カラム編集」>「このカラムに基づいてカラムを追加…」をクリックし、「新しいカラム名」に以下5項目の左端(date等)を入力し、式(expression)ボックスに、それぞれに対応する式(value.parseJson()[‘date’]等)を入力してください。以下の5つをそれぞれを作成します。]
- “date”,
value.parseJson()['date'] - “title”,
value.parseJson()['title'] - “city”,
value.parseJson()['city'].join(", ") - “lccn”,
value.parseJson()['lccn'] - “text”,
value.parseJson()['ocr_eng']
米国議会図書館のOCR化テキストデータの出力に最近加えられた変更によって、テキスト列に予期しない改行が入ることが一部のユーザから指摘されています。これらは、value.replace("\n","")式を使うことで、削除できます。(2022年11月追記)
必要な情報が抽出されたら、itemsのカラムでカラム編集 > このカラムを取り除くを選択して、itemsのカラムを削除しましょう。
各カラムは、他のGREL変換を使用してさらに改良することができます。例えば、dateをより読みやすい形式に変換するには、GRELの日付関数を使用します。dateカラムをvalue.toDate("yyyymmdd").toString("yyyy-MM-dd")という式で変換します。
もう1つの一般的なワークフローは、さらなるURLクエリでデータを拡張することです。例えば、新聞各号の全情報へのリンクをlccnに基づいて作成することができます。"https://chroniclingamerica.loc.gov/lccn/" + value + "/" + cells['date'].value + "/ed-1.json"という式を使用して、lccnカラムに基づく新しい列を作成します。このURLをフェッチすると、issueのページの完全なリストが返されます。 ともかくも今のところは、ノースウェストの1865年のヘッドラインをお楽しみください!
<事例3 省略>
ウェブ上のデータやサービスにアクセスすることで、人文科学の研究に新たな可能性と効率がもたらされています。強力なものですが、これらのAPIは人文科学を対象としていないことが多く、私たちの探究にとって適切でない、あるいは最適化されていない可能性があります。学習データが不完全であったり、偏っていたり、秘匿されていたりすることもあるのです。私たちは常にこれらのデータ集約やアルゴリズムに対して疑問を投げかけ、それらが生み出すことのできる指標というものについて、批判的に考える必要があります。これは新しい技術的なスキルではなく、歴史研究者の伝統的な専門知識の応用であり、偏りを解きほぐし行間を読むために現物の一次史料を調査するのと同じことなのです。人文学の研究者は日常的に、重要な物語を語るために複雑に入り組んだ資料を統合し、評価しています。私たちは、自分たちの疑問や手法にとってより適した新しいものを作り出すのと同じように、データソース、アルゴリズム、APIサービスを批判的に評価することが可能なのです。
Refineは、生データの集計から分析まで、インタラクティブにデータを扱うことができるユニークな機能を備えており、探索的な研究をサポートし、表形式データへの素晴らしく流動的で遊び心のあるアプローチを提供します。OpenRefineは柔軟で実用的なツールであり、ルーチンワークを簡単にし、専門領域の知識と組み合わせることで研究力の拡張に貢献するものなのです。
[1] David Huynh, “Google Refine”, Computer-Assisted Reporting Conference 2011, http://web.archive.org/web/20150528125345/http://davidhuynh.net/spaces/nicar2011/tutorial.pdf.
著者について
Evan Peter Williamson は、アイダホ大学図書館のデジタル・インフラストラクチャー・ライブラリアンであり、データ&デジタル・サービスと連携して、クールなプロジェクト、啓発的なワークショップ、革新的なサービスを実現している。美術史、古典研究、文書館のバックグラウンドを持ちながら、常にデジタル関連のあらゆることに携わっている。
引用の際はこちらをご利用ください
<原著>
Evan Peter Williamson, “Fetching and Parsing Data from the Web with OpenRefine,” Programming Historian 6 (2017), https://doi.org/10.46430/phen0065.
<翻訳記事>
Evan Peter Williamson著, 菊池信彦訳. <抄訳>OpenRefineを利用したウェブからのデータ取得とその解析. DH研究情報ポータル. 2023. https://dhportal.ac.jp/?p=1617.

この 作品 は クリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。