Google Colabratoryで公開しているこの「廣瀬本万葉集TEI/XMLデータ分析入門」のレッスンノートは、国文学研究資料館および関西大学との共同研究「廣瀬本万葉集TEI/XML作成プロジェクト」で作成途中の同データについて、データ分析および利活用の方法について、その手順をまとめたものです。
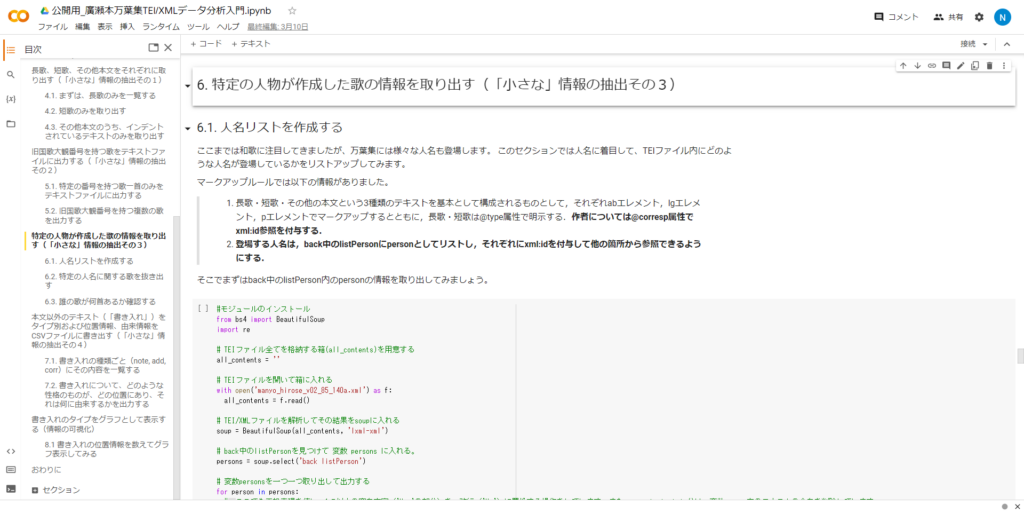
レッスンは、廣瀬本万葉集TEI/XMLデータからテキスト部分全体、すなわち「大きな」情報の抽出方法を紹介し、その後、ユーザ自身が必要とする和歌や人名、「書き入れ」等の「小さな」情報を抽出する方法へと段階的に進む構成としています。
このノートの想定読者は、Pythonやデータ分析の扱いに慣れていない人文学研究者や学生です。それらの読者に対して、ステップバイステップで、データから求める情報の抽出方法を紹介するのが、本レッスンの目的です。
研究者あるいは学生ご自身の自主学習用に、あるいは、講義での素材として、広く活用されることを願っております。